Le modèle relationnel de Gompertz
Description de la méthode
La méthode relationnelle de Gompertz est un perfectionnement de la méthode du quotient P/F de Brass qui cherche à estimer les taux de fécondité par âge et l’indice synthétique de fécondité en déterminant la forme de la courbe de fécondité à partir des données sur les naissances récentes recueillies dans des recensements ou des enquêtes, son niveau étant fixé d’après les parités moyennes déclarées par les jeunes femmes.
En faisant ces estimations, la méthode cherche à corriger les erreurs couramment rencontrées dans les données de fécondité, lorsque trop ou trop peu de naissances sont déclarées au cours de la période de référence et que les descendances sont sous-déclarées et qu’il y a des erreurs de déclaration des âges chez les femmes âgées. Ces erreurs sont décrites en détail dans la section sur l’évaluation de la qualité des données de fécondité.
La méthode repose sur une propriété utile d’une distribution (cumulée) de Gompertz,
, qui est sigmoïdale (c’est-à-dire en forme de S), mais qui a aussi une fonction associée de risque, asymétrique à droite et qui saisit donc assez bien à la fois la distribution des parités moyennes par âge des femmes et leur fécondité cumulée. La forme de G(x) implique qu’une double transformation logarithmique négative des fécondités cumulées proportionnelles ou des parités moyennes s’approche d’une ligne droite sur l’essentiel de l’intervalle des âges. La double transformation logarithmique,
est intitulée gompit et présente une étroite analogie avec la transformation logit fréquemment utilisée dans l’analyse de la mortalité. Mais Brass a montré qu’on pouvait obtenir un ajustement beaucoup plus proche de la linéarité en utilisant un modèle relationnel qui exprime les gompits d’une série observée de données de fécondité comme une fonction linéaire des gompits d’une distribution de fécondité standard définie. En d’autres termes,
où est le gompit d’une distribution standard de fécondité. Evidemment, si α = 0 and β = 1, la distribution de fécondité sera identique au schéma standard. Alpha (α) indique la mesure dans laquelle l’âge à la maternité dans la population diffère de l’âge dans le standard (des valeurs négatives impliquent des âges plus élevés que dans le standard), alors que béta (β) est une mesure de la dispersion de la fécondité (des valeurs supérieures à 1 correspondent à une distribution plus resserrée).
La méthode nécessite de connaître les parités moyennes dans chaque groupe d’âge, pour x= 15, 20, …, 45, et les taux de fécondité dans chaque groupe d’âge, .
Pour simplifier l’exposé, et pour distinguer clairement les données de descendance et de fécondité récente, est intitulé P(1), P(2) et ainsi de suite. La section du manuel traitant de l’évaluation de la qualité des données de fécondité explique comment ces éléments sont tirés des données de recensement. Comme avec d’autres méthodes, les parités moyennes doivent être ajustées pour la correction d’el Badry si nécessaire.
La fécondité du moment cumulée jusqu’au terme de chaque groupe d’âge est égale à
La méthode originellement proposée par Brass (1978) utilisait la série des gompits du rapport entre fécondité cumulée au terme de chaque groupe d’âge et taux de fécondité cumulés jusqu’à 50 ans (c’est-à-dire indice synthétique de fécondité, TF), courbe de forme sigmoïdale avec un minimum de 0 et un maximum de 1 (au dernier groupe d’âge). Les gompits des parités moyennes sont obtenus de la même façon.
Il y a deux faiblesses inhérentes à cette démarche. Premièrement, elle nécessite la connaissance de l’indice synthétique de fécondité et les estimations de l’indice synthétique de fécondité tirées des taux de fécondité par âge peuvent être biaisées. En fait, l’indice synthétique de fécondité est souvent le paramètre que l’analyste cherche en priorité à estimer. La seconde faiblesse est l’hypothèse implicite de fécondité constante au fil du temps qui résulte du traitement des gompits de parité. Néanmoins, la formulation de Brass est à l’origine du développement par Booth (1980, 1984) de la distribution de fécondité standard, qui est utilisé dans le modèle encore aujourd’hui.
La reformulation de la méthode par Zaba (1981) traite largement le problème de ces deux limites, en évitant la circularité de la méthode initiale et en abandonnant l’hypothèse de fécondité constante. Un travail ultérieur non publié de Zaba a généralisé la démarche pour incorporer des variantes du modèle (dont certaines sont décrites ici). Nous faisons plus loin un exposé complet de la reformulation de Zaba. Mais en résumé elle montre que le modèle peut s’exprimer comme
(1)
où e(x), g(x) et c sont des fonctions du standard retenu et z(x) est le gompit des rapports entre deux mesures successives de la fécondité cumulée par période, c’est-à-dire F(x)/F(x+5), au lieu de F(x)/F50 comme Brass le suggérait à l’origine.
En d’autres termes,
Pour les données de parité, le modèle est ajusté sur les rapports de parités moyennes successives, P(i)/P(i+1). Ceci signifie que le modèle peut être utilisé sans qu’il soit besoin d’estimer l’indice synthétique de fécondité avant d’ajuster les paramètres de forme. Il découle de l’équation 1 qu’une représentation graphique de z(x) - e(x) en fonction de g(x) doit être une droite de pente β et d’ordonnée à l’origine
(En notant que β devrait être proche de l’unité, les premières formulations de la procédure tendaient à négliger le second terme de l’ordonnée à l’origine, réduisant celle-ci à alpha. Avec les capacités de calcul aujourd’hui disponibles, cette perte de précision dans le calcul de l’ordonnée à l’origine n’a plus lieu d’être. La nécessité que β soit proche de l’unité demeure néanmoins).
Le même raisonnement s’applique à l’évaluation des données de parité. En utilisant P(i)/P(i+1), le rapport des parités moyennes dans deux groupes d’âge consécutifs, l’équation linéaire rattachant z(i) - e(i) à g(i) donne
(2)
Par convention, on appelle P-points les points tirés des données de parité et F-points ceux tirés des taux de fécondité. La procédure d’ajustement a pour but de trouver une combinaison cohérente des P- et des F-points, les deux séries de points définissant à peu près les mêmes droites, et de déterminer ensuite grâce à ceux-ci conjointement les paramètres α et β des équations 1 et 2 ci-dessus. Les valeurs de α et β permettent d’établir les gompits relationnels, , et de même pour Y(i).
L’obtention d’une distribution de fécondité ajustée par la méthode relationnelle de Gompertz nécessite des tableaux de parités moyennes et de taux de fécondité par âge. Les taux de fécondité sont cumulés et les rapports des valeurs cumulées successives sont calculés. Les rapports des parités moyennes successives sont également calculés. Les gompits de ces rapports sont calculés et utilisés pour établir le graphique des deux paires de points, z(x) - e(x) en fonction de g(x), et z(i) - e(i) en fonction de g(i). Les droites d’ajustement auront des pentes égales à β, et une ordonnée à l’origine dont l’expression inclut α, β and c, d’où on pourra tirer α. Les valeurs de α et β sont utilisées pour transformer les gompits des cumulants standards en gompits ajustés, qui sont ensuite convertis en parités moyennes et taux de fécondité ajustés. Le niveau de la fécondité est déterminé par les points de parité les plus fiables. Ce sont généralement ceux des femmes âgées de 20-29 ou 20-34 ans, qui sont les moins sujettes à omettre des naissances et à déclarer des âges erronés comme peuvent l’être les femmes plus âgées.
Le recours au modèle relationnel de Gompertz pour calculer une distribution ajustée de la fécondité présente un certain nombre d’avantages par rapport à la méthode du quotient P/F utilisée antérieurement. Le modèle utilise une distribution de fécondité fiable pour des régimes de fécondité moyenne ou élevée (le standard de Booth). Ainsi, les taux de fécondité douteux estimés à partir des déclarations de naissances de l’année écoulée peuvent être remplacés par des valeurs-types ajustées en utilisant les points les plus fiables. La représentation graphique des deux séries de points est un guide précieux pour établir la fiabilité de chaque point ; elle peut suggérer quelles sont les données erronées et aider à identifier les tendances de la fécondité. Tous les points fiables peuvent servir à établir la distribution modèle ajustée. Le modèle fournit aussi un moyen fiable d’interpolation utile lors de l’établissement de données de parité ou de fécondité cumulée comparables et de conversion des taux de fécondité dans des groupes d’âge non conventionnels en taux dans des groupes d’âge conventionnels.
Données nécessaires et hypothèses
Tableaux des données nécessaires
- Taux de fécondité pour les 12, 24 ou 36 mois précédant l’enquête, classés par âge de la mère à l’enquête ou âge à la naissance de l’enfant, ou
- nombre de femmes à la date du recensement ou de l’enquête par groupe quinquennal, et
- nombre de naissances des femmes dans les 12, 24 ou 36 mois précédant l’enquête par groupe quinquennal d’âge.
- Parités moyennes des femmes, classées par groupe quinquennal d’âge de la mère, ou
- nombre de femmes par groupe quinquennal et
- nombre total d’enfants nés de ces femmes, par groupe quinquennal d’âge.
Hypothèses importantes
- Le schéma de fécondité standard choisi pour la procédure d’ajustement reflète de façon appropriée la forme de la distribution de la fécondité dans la population.
- Les changements de la fécondité ont été réguliers et graduels et ont affecté tous les groupes d’âge dans une mesure comparable.
- Les erreurs dans les taux de fécondité avant ajustement sont proportionnellement les mêmes parmi les femmes dans les groupes d’âge centraux (20-39 ans), de sorte que la forme de la fécondité par âge des naissances récentes déclarées est raisonnablement correcte.
- Les parités déclarées par les jeunes femmes (20-29 ou 20-34 ans) sont conformes à la réalité.
La méthode permet généralement de détecter les violations de ces hypothèses.
Travail préparatoire et recherches préliminaires
Avant d’entreprendre l’analyse des niveaux de fécondité en recourant à cette méthode, l’analyste doit vérifier la qualité des données au moins sur les points suivants :
- structure par âge et sexe de la population ;
- naissances déclarées au cours de l’année écoulée, et
- parités moyennes et nécessité d’une correction d’el Badry.
Avertissements et mises en garde
- Lors de l’application de cette méthode, l’analyste doit faire particulièrement attention à vérifier et à spécifier correctement la définition utilisée pour classer les mères par âge.
- Chaque fois que c’est nécessaire, les parités moyennes doivent être corrigées en utilisant la correction d’el Badry, suite au classement erroné des femmes sans enfants dans la catégorie des parités non déclarées.
- La méthode peut être utilisée avec des données agrégées sur une période de trois ans. Une vigilance particulière est toutefois nécessaire dans l’utilisation du modèle complet (par opposition à son utilisation pour un simple lissage) avec des données largement supérieures à un an. Dans l’idéal, les nombres de personnes-années exposées au risque devraient alors être calculés. En outre, il existe une possibilité accrue de naissances multiples au cours d’une période prolongée et la formulation de la question dans le recensement ou l’enquête risque d’être mal adaptée à l’identification de tels cas.
- Si des pondérations liées au plan d’échantillonnage ont été fournies en même temps que les données, elles doivent être appliquées de manière adaptée au logiciel statistique lors de la préparation des tableaux nécessaires au modèle.
- La méthode est contre indiquée lorsque la forme de la distribution de fécondité à modéliser diffère largement de celle qui sous tend le standard de fécondité. Les paramètres α et β définissant la forme et la position de la distribution de fécondité, Zaba (1981) recommande de n’utiliser le modèle que si -0.3 < α < 0.3 et 0.8 < β < 1.25. Un autre standard devrait être choisi si α et β se situent hors de ces intervalles.
- Certaines des approximations utilisées pour établir les équations d’estimation fonctionnent moins bien dans les groupes d’âge les plus jeunes et les plus avancés que chez les femmes d’âge moyen, en particulier lorsque le schéma de fécondité déclarée diffère radicalement du standard. Les points correspondant aux déclarations des femmes de ces âges doivent donc être traités avec des précautions particulières. L’impact sur les estimations de l’indice synthétique de fécondité est toutefois limité.
Application de la méthode
L’application de la méthode se fait selon les étapes suivantes.
Etape1 : Calcul des parités moyennes déclarées
Calculer les parités moyennes, des femmes de chaque groupe d’âge (x, x+5), pour x =15, 20 45, si ça n’a pas déjà été fait lors des recherches préliminaires, ou produit comme conséquence de l’application de la correction d’el Badry. Le calcul et la correction des parités moyennes sont décrits dans la section sur l’évaluation de la qualité des données de parité.
Etape 2 : Détermination du classement de l’âge des mères
Selon les données disponibles, les taux de fécondité peuvent être classés soit d’après l’âge des mères à la date d’enquête, soit par leur âge à la naissance de leur enfant. Le premier cas est presque systématique avec les données de recensement, où l’âge des mères est celui qu’elles avaient à la date du recensement. Le second cas est plus courant avec les données administratives tirées des systèmes d’enregistrement à l’état civil. Il est essentiel que ce classement soit connu car une définition incorrecte biaise les estimations de taux.
La feuille de calcul associée au modèle peut traiter aussi bien les données sans décalage (c’est-à-dire déclarées selon l’âge des mères à la naissance) que, - dans le cas de données classées selon l’âge des mères à la date d’enquête – avec une demi-année, une année ou une année et demie de décalage (pour des périodes respectives de 12, 24 et 36 mois avant l’enquête).
Etape 3 : Calcul des taux de fécondité par âge
Les taux de fécondité par âge sont obtenus en divisant les naissances déclarées au cours de la période choisie (par exemple l’année, deux ans ou trois ans) avant la date d’enquête par le nombre de femmes dans chaque groupe d’âge.
Etape 4 : Choix du standard de fécondité à appliquer et de la variante du modèle à ajuster
Par défaut, le standard de fécondité est celui de Booth, légèrement modifié par Zaba (1981). Il est approprié dans le cas des populations à fécondité moyenne et élevée ; il est exprimé sous forme d’un schéma normalisé de fécondité cumulée (c’est-à-dire avec une fécondité totale égale à un). Les valeurs standards de Ys(x) sont déterminées en prenant les gompits de la distribution et les valeurs des parités standards, Ys(i), sont les gompits des parités associées au schéma standard de fécondité. Le choix du standard détermine les valeurs de g() et e() utilisées dans les procédures d’ajustement par régression qui sont tirées algébriquement de Ys().
Deux variantes du modèle relationnel de Gompertz sont présentées ici. L’option par défaut consiste à faire les mêmes hypothèses sur la nature des erreurs inhérentes aux données de fécondité que dans la méthode P/F de Brass, à savoir que les déclarations de fécondité récente souffrent d’erreurs sur la période de référence et de sous-déclaration qui sont indépendantes de l’âge, alors que les déclarations de descendance souffrent d’omissions qui s’accroissent avec l’âge. Sur la feuille de calcul, cette variante est intitulée ‘Forme F – Niveau P’.
Dans une seconde variante, on utilise le modèle relationnel de Gompertz pour corriger des éventuelles distorsions dans la forme de la distribution de fécondité, alors qu’on laisse le niveau inchangé. Si on suspecte des erreurs sur la période de référence ou une sous-déclaration, cette variante ne donnera pas une estimation plausible de la fécondité.
Etape 5 : Evaluer la représentation graphique des P-points et des F-points
Les représentations graphiques de z(x) - e(x) en fonction de g(x), et z(i) - e(i) en fonction de g(i) sur le même système d’axes permettent de faire apparaître des erreurs communes et des tendances dans les données (voir plus loin).
Etape 6 : Ajustement du modèle par sélection des points à utiliser
Au départ, tous les points doivent être inclus dans le modèle, sauf si la parité moyenne dans un groupe d’âge est supérieure à celle dans le groupe d’âge suivant. Dans ce cas, le gompit n’est pas défini et le modèle ne peut pas être ajusté en utilisant ce point (une telle situation ne peut pas survenir dans une cohorte réelle, mais elle peut le faire à cause d’erreurs dans les données ou dans une cohorte synthétique dans une période où la fécondité évolue rapidement).
Si les données de parité et de fécondité sont mutuellement cohérentes, les représentations graphiques des z() - e() en fonction de g() doivent se situer sur une droite. Les P-points et les F-points qui s’écarte d’une ligne droite doivent être exclus du modèle. Une régression par les moindres carrés ordinaires est utilisée pour ajuster des droites sur les P-points et les F-points et pour identifier, séquentiellement, les points qui ne se situent pas nettement sur une droite. Il s’agit de chercher la combinaison la plus large de P- et F-points (à peu près) alignés, et d’utiliser ceux-ci pour ajuster le modèle.
On retient ou on exclut des points en respectant les instructions suivantes :
- Une série de points contigus doit être incluse dans le modèle. Seuls des points extrêmes peuvent être exclus. (La raison est que chaque point sur le graphique est le résultat d’un calcul de ratio entre les valeurs de données adjacentes. Si l’analyse conduit à considérer une donnée comme non fiable en tant que dénominateur, il n’est pas logique de l’accepter comme numérateur du ratio suivant.)
- Il vaut mieux éliminer des P-points que des F-points, car les données de parité moyenne sont davantage sujettes à des erreurs liées à l’âge que les données de fécondité.
- Les P-points qui s’écartent de l’alignement construit seulement sur les autres P-points, ainsi que les F-points qui s’écartent de l’alignement construit seulement sur les autres F-points doivent être éliminés dès le début du processus d’ajustement.
- Il vaut mieux éliminer les P- et les F-points aux âges avancés plutôt qu’aux jeunes âges car les données y sont généralement moins fiables et présentent moins de cohérence entre descendance et fécondité récente. Les données relatives aux femmes de moins de 20 ans font cependant exception, car elles reposent sur des nombres faibles d’événements, ce qui rend souvent peu fiables les estimations des parités moyennes ou de la fécondité cumulée.
Un ajustement réalisé sur un nombre élevé de points est préférable à un ajustement réalisé sur un faible nombre de points, même s’il est légèrement moins bon. La feuille de calcul produit l’écart quadratique moyen
à partir des points utilisés pour ajuster le modèle. Cette statistique peut aider à déterminer le nombre optimal de points sur lesquels réaliser l’ajustement, s’il y a un doute dans le choix à faire entre deux modèles concurrents. Dans ce cas, on peut choisir celui qui a le plus faible écart quadratique.
Etape 7 : Evaluer la qualité des paramètres estimés
Les valeurs de α et β, qui représentent la droite de meilleur ajustement joignant les P-points et les F-points restants, nécessitent un contrôle pour vérifier qu’elles ne s’éloignent pas de leurs valeurs centrales à un point tel que le choix du standard serait mis en cause. Un bon ajustement est obtenu si -0.3 < α < 0.3, et si 0.8 < β < 1.25.
Si les paramètres se situent en dehors de ces intervalles, au moins une des séries de données sous-jacentes pose problème ou le standard est inadéquat. Il convient alors d’essayer un autre standard (voir plus loin) ou de modifier la sélection des points avant de procéder plus avant. Si les paramètres sont toujours en dehors des intervalles ci-dessus, il faut alors considérer que la méthode n’est pas appropriée.
Etape 8 : Taux de fécondité par âge et indice synthétique de fécondité ajustés
Une fois estimés les deux paramètres du modèle, ceux-ci peuvent être appliqués au standard des parités pour fournir des valeurs ajustées . Celles-ci sont ensuite ramenées à des mesures de la proportion cumulée de fécondité réalisée par groupe d’âge i, grâce à la transformation anti-gompit. Les anti-gompits reposant sur les distributions de parité indiquent la proportion de fécondité réalisée dans le groupe d’âge. En divisant la parité observée dans chaque groupe d’âge par ces proportions, on obtient une série d’estimations de l’indice synthétique de fécondité. La moyenne de ces valeurs calculée sur le sous-ensemble des groupes d’âge qui ont été utilisés pour estimer α et β donne l’estimation ajustée de l’indice synthétique de fécondité, .
En appliquant les mêmes α et β aux gompits standards pour les âges qui bornent les groupes d’âge conventionnels (c’est-à-dire 20, 25 …50), en appliquant la transformation anti-gompit, et en multipliant par , on obtient une distribution ajustée de la fécondité cumulée. En faisant la différence entre les estimations successives de la fécondité cumulée et en la divisant par cinq, on obtient un schéma de fécondité ajusté pour les groupes d’âge conventionnels (15-19 ; 20-24 etc.), même si le classement des données initiales était décalé d’une demi-année.
(Si le modèle a été ajusté en utilisant seulement les F-points, α et β ne sont définis que par la F-droite. La distribution de fécondité lissée est obtenue par une série d’étapes semblable à celle décrite précédemment, sauf que les proportions ajustées sont multipliées par le niveau de fécondité estimé à partir des données récentes elles-mêmes, plutôt que par une estimation fondée sur les données de parité.)
Interprétation et diagnostics
Erreurs classiques dans les données
Les points tirés des données relatives aux femmes de moins de 20 ans sont souvent peu fiables, car les événements sont généralement peu nombreux et sujets à diverses erreurs de déclaration (par exemple, les agents recenseurs attribuent un âge plus élevé aux mères adolescentes). Il est donc courant que les droites ajustées aux P- et F- points conviennent mieux aux femmes en pleine période féconde (20-34 ans) qu’aux très jeunes et aux plus âgées. Si les P-droites et les F-droites ne convergent pas, même dans l’intervalle 20-34 ans, il est probable qu’il y a des erreurs dans au moins une des séries de données, même à ces âges, ou que des variations (importantes) ont affecté la fécondité récemment.
Une représentation graphique de l’ensemble des P-points et des F-points donne des informations sur les erreurs dans les données et sur les tendances récentes de la fécondité. En interprétant les graphiques, on se souviendra que les valeurs de z() - e() (sur l’axe des ordonnées) varient avec les distributions observées de fécondité et de parité, mais pas les valeurs de g() (qui ne s’appuient que sur le standard). De même, z() - e() varie dans le même sens que les ratios qui le sous-tendent.
Les types de problèmes les plus courants mis en lumière par la représentation graphique sont l’omission d’enfants dans les déclarations de parité des femmes âgées, la surestimation des âges et une indication de baisse récente de la fécondité.
Zaba (1981) a utilisé des données simulées sur la base du standard de Booth pour étudier l’effet des erreurs de données et des variations de la fécondité sur les représentations graphiques. Les résultats sont présentés ci-dessous.
1. Les femmes âgées omettent des enfants en déclarant leur descendance
Si les femmes âgées omettent des enfants en déclarant leur descendance finale, les valeurs de P seront trop élevées (le dénominateur de chaque cumulant étant trop faible) par rapport à la droite attendue et les P-points auront tendance à s’incurver vers le haut aux âges élevés.
2. Sur-déclaration des naissances ou exagération des âges par les femmes âgées
Ces deux types d’erreur ont le même effet, qu’un nombre erroné de naissances soit déclaré par les femmes âgées ou que des femmes jeunes (qui ont une fécondité récente élevée) soient considérées comme plus âgées qu’elles ne le sont dans la réalité. Il en résulte une courbe F qui s’incurve vers le bas aux âges avancés.
3. Tendances de la fécondité
La divergence entre les P-points et les F-points sur le graphique peut révéler une évolution du niveau de la fécondité. Si la fécondité baisse, les cumulants de F sont plus élevés que les cumulants de P au même âge, et les F-points ont une pente plus forte que les P-points. Un diagnostic de baisse de la fécondité est possible quand les F-points s’alignent au-dessus de la droite des P-points et vice versa.
Des variations rapides de la fécondité qui affectent les jeunes âges à la maternité empêchent généralement les P-points et les F-points de s’aligner sur une même ligne, même après avoir exclu la plupart des P-points de l’ajustement. L’élimination successive des P-points qui ne s’alignent pas sur les P-points et les F-points suggère un changement rapide et récent de la fécondité aux jeunes âges.
Des graphiques diagnostiques, reposant sur le standard de Booth, sont représentés sur la figure 1.
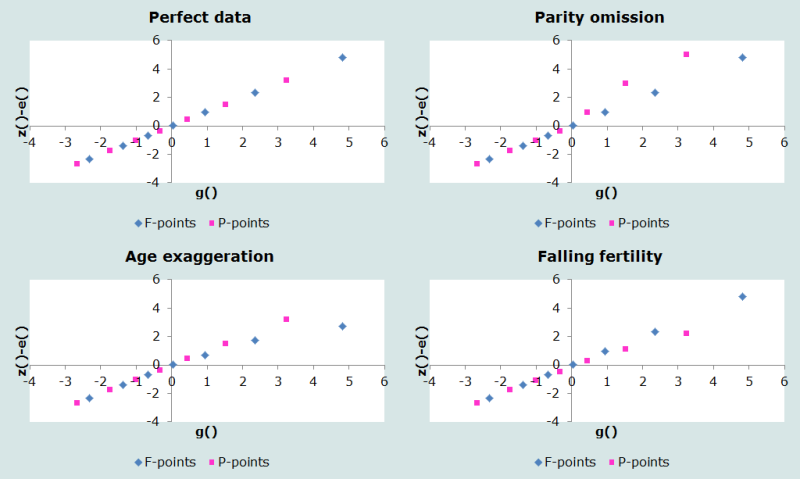
Comme on le voit, si les femmes âgées omettent des naissances vivantes, les P-points à droite sur l’échelle (ceux des âges avancés) dérivent vers le haut. Quand les femmes se déclarent (ou sont déclarées) plus âgées qu’elles ne le sont, la ligne F s’incurve vers le bas aux âges avancés. Enfin, si la fécondité baisse, les F-points sont en général au dessus des P-points.
En traitant de données réelles, on est souvent confronté à un mélange d’erreurs et de tendances qui peut être beaucoup plus compliqué que les archétypes présentés ici. Des erreurs importantes peuvent masquer des tendances réelles et la méthode ne doit donc pas être appliquée aveuglément.
Quotients P/F
La méthode du quotient P/F n’est pas présentée dans ce manuel, mais les ratios qui découlent de l’application de la méthode donnent des indications utiles sur les tendances récentes de la fécondité. Ils peuvent aussi servir de guides lorsqu’il s’agit d’évaluer l’applicabilité de certaines méthodes d’estimation de la mortalité infantile.
On peut tirer facilement d’un modèle relationnel de Gompertz ajusté des pseudo-quotients pour chaque groupe d’âge
Le numérateur est la parité moyenne observée dans chaque groupe d’âge, alors que le dénominateur utilise les valeurs de α et β tirées des seuls F-points (à peu près comme dans la variante F-seulement du modèle) pour modifier le gompit standard au point médian de chaque groupe d’âge. L’anti-gompit est ensuite amené proportionnellement au niveau de l’indice synthétique de fécondité qu’impliquent les F-points retenus dans le modèle. On ne calcule pas le quotient aux plus jeunes âges, où les parités moyennes sont généralement très basses, comme l’est la fécondité cumulée à 17,5 ans, rendant ainsi le quotient instable dans ce groupe d’âge.
Ces quotients P/F peuvent être représentés graphiquement en ordre inversé, de sorte que le groupe d’âge le plus élevé se situe à gauche. La série des quotients P/F peut alors être lue comme un déroulement chronologique de gauche à droite (puisque, en général, la fécondité des femmes âgées s’est produite avant celle des femmes jeunes). Des écarts importants par rapport à la tendance générale suggèrent des erreurs dans les données. La décroissance des quotients P/F représentés de cette façon révèle une divergence croissante avec l’âge entre les mesures de la fécondité par cohorte et par période; elle est donc indicative d’une baisse de la fécondité.
Exemple
Cette illustration de la méthode recourt à des données présentées dans le rapport sur la fécondité tiré du recensement de 2008 au Malawi. La méthode est mise en œuvre dans un classeur Excel.
Etape1 : Calcul des parités moyennes déclarées
Les parités moyennes figurent au tableau 2.6 du rapport sur la fécondité du recensement de 2008 au Malawi. Le rapport ne précise pas si les parités ont été corrigées ou si une correction d’el Badry a été appliquée aux données. Les données sont ici au tableau 1 :
Tableau1 Mesures de la fécondité tirées du recensement de 2008 au Malawi
Age (à l’enquête) | Parité moyenne par femme | Taux de fécondité par période |
|---|---|---|
15-19 | 0,283 | 0,111 |
20-24 | 1,532 | 0,245 |
25-29 | 2,849 | 0,230 |
30-34 | 4,185 | 0,195 |
35-39 | 5,214 | 0,147 |
40-44 | 6,034 | 0,072 |
45-49 | 6,453 | 0,032 |
Etape 2 : Détermination du classement de l’âge des mères
La question sur la fécondité récente au recensement de 2008 au Malawi était « Combien de naissances vivantes au cours des 12 derniers mois ? ». Comme on ne peut pas dater la naissance de l’enfant, on peut supposer que les données sont classées par âge de la mère à la date du recensement plutôt qu’à la naissance de son enfant.
Etape 3 : Calcul des taux de fécondité par âge
Les taux de fécondité sont présentés au tableau 2.6 du rapport sur la fécondité du recensement de 2008 au Malawi. (Le calcul de ces taux, présenté au tableau 2.3 du rapport, donne à penser que 5f20 était 0,250, mais les taux du tableau 2.6 sont conservés pour cet exemple de façon à permettre une meilleure comparaison des résultats obtenus).
Etape 4 : Choix du standard de fécondité à appliquer et de la variante du modèle à ajuster
En l’absence d’alternative, nous appliquons le standard de Booth, et – afin de corriger la forme et le niveau des données de fécondité, nous choisissons d’ajuster la variante Forme-F Niveau P. Les coefficients, e() et g(), sont calculés dans les tableaux 2-4 ci-dessous.
Tableau 2 Calcul de e(x) et g(x) quand les données sont décalées d’une demi-année
Age x | Fs(x)/F | Ys(x) | Ratio | Phi | Phi' | Phi'' | e(x) | g(x) |
|---|---|---|---|---|---|---|---|---|
[1] | [2] | [3] | [4] | [5] | [6] | [7] | [8] | [9] |
=gompit[2] | =Ys(x)/Ys(x+5) | =gompit[4] | =[5]-[6] | =[6] | ||||
14 ½ | 0,0011 | -1,9228 | 0,0094 | -1,5410 | -2,4565 | 0,9155 | -2,4565 | |
19 ½ | 0,1140 | -0,7753 | 0,3233 | -0,1216 | -1,4527 | 0,9563 | 1,3311 | -1,4527 |
24 ½ | 0,3528 | -0,0411 | 0,6007 | 0,6741 | -0,7426 | 0,9632 | 1,4167 | -0,7426 |
29 ½ | 0,5872 | 0,6305 | 0,7529 | 1,2592 | -0,0364 | 0,9530 | 1,2957 | -0,0364 |
34 ½ | 0,7800 | 1,3925 | 0,8479 | 1,8021 | 0,8405 | 0,9615 | 0,8405 | |
39 ½ | 0,9199 | 2,4830 | 0,9298 | 2,6209 | 2,1799 | 0,4409 | 2,1799 | |
44 ½ | 0,9893 | 4,5323 | 0,9893 | 4,5324 | 4,5315 | 0,0010 | 4,5315 | |
Phi’’-barre |
|
|
|
|
| 0,9575 |
|
|
Les valeurs du standard figurant dans la colonne [2], on calcule les gompits du standard dans la colonne [3]. Par exemple, dans le groupe d’âge qui se termine à 19,5 ans, c’est -ln(-ln(0,1140)) = -0,7753. On notera que les valeurs cumulées s’appliquent à 14,5 ans, 19,5 ans etc., reflétant ainsi le décalage d’une demi-année dans le classement des âges des mères. Les rapports de la fécondité cumulée à deux âges successifs tirée du standard de la colonne [2] figurent à la colonne [4] et leurs gompits à la colonne [5]. Ainsi dans le groupe d’âge se terminant à 39,5 ans, on a 2,6209 = -ln(-ln(0,9298)) = -ln(-ln(0,9199/0,9893)).
Les dérivées premières et secondes au point où β = 1, figurant aux colonnes [6] et [7], sont évaluées grâce aux formules :
Enfin e(x) est obtenu dans la colonne [8] en retranchant la colonne [6] de la colonne [5].
Tableau 3 Calcul de e(x) et g(x) quand les données ne sont pas sujettes à un décalage des âges
Age x | Fs(x)/F | Ys(x) | Ratio | Phi | Phi' | Phi'' | e(x) | g(x) |
|---|---|---|---|---|---|---|---|---|
[1] | [2] | [3] | [4] | [5] | [6] | [7] | [8] | [9] |
15 | 0,0028 | -1,7731 | 0,0204 | -1,3591 | -2,3278 | 0,9688 | -2,3278 | |
20 | 0,1358 | -0,6913 | 0,3600 | -0,0214 | -1,3753 | 0,9582 | 1,3539 | -1,3753 |
25 | 0,3773 | 0,0256 | 0,6200 | 0,7379 | -0,6748 | 0,9629 | 1,4127 | -0,6748 |
30 | 0,6086 | 0,7000 | 0,7644 | 1,3143 | 0,0393 | 0,9510 | 1,2750 | 0,0393 |
35 | 0,7962 | 1,4787 | 0,8559 | 1,8607 | 0,9450 | 0,9157 | 0,9450 | |
40 | 0,9302 | 2,6260 | 0,9378 | 2,7455 | 2,3489 | 0,3966 | 2,3489 | |
45 | 0,9919 | 4,8097 | 0,9919 | 4,8098 | 4,8086 | 0,0012 | 4,8086 | |
Phi’’-barre |
|
|
|
|
| 0,9574 |
|
|
Le tableau 3 répète les mêmes calculs, mais pour des données sans décalage ; ces valeurs sont nécessaires pour obtenir les estimations de fécondité finales, sans décalage. Le tableau 4 montre comment sont calculées les valeurs de e(i), g(i) et c à utiliser avec les données de parité, en utilisant les parités tirées du standard pour débuter dans la colonne [2].
Tableau 4 Calcul des e(i) et g(i) à partir des données de parité
Age i | Ps(i) | Ys(i) | Ratio | Phi | Phi' | Phi'' | e(i) | g(i) |
|---|---|---|---|---|---|---|---|---|
[1] | [2] | [3] | [4] | [5] | [6] | [7] | [8] | [9] |
=gompit[2] | =Ys(i)/ | =gompit[4] |
| =[5]-[4] | =[6] | |||
0 | 0,0003 | -2,0961 | 0,0056 | -1,6449 | -2,6738 | 1,0289 | -2,6738 | |
1 | 0,0521 | -1,0833 | 0,2044 | -0,4622 | -1,7469 | 0,9519 | 1,2846 | -1,7469 |
2 | 0,2549 | -0,3124 | 0,5143 | 0,4081 | -1,0159 | 0,9638 | 1,4240 | -1,0159 |
3 | 0,4957 | 0,3541 | 0,7014 | 1,0367 | -0,3349 | 0,9597 | 1,3717 | -0,3349 |
4 | 0,7067 | 1,0579 | 0,8140 | 1,5810 | 0,4406 | 1,1404 | 0,4406 | |
5 | 0,8681 | 1,9561 | 0,8969 | 2,2184 | 1,5162 | 0,7022 | 1,5162 | |
6 | 0,9679 | 3,4225 | 0,9701 | 3,4943 | 3,2238 | 0,2705 | 3,2238 | |
Phi’’-barre |
|
|
|
|
| 0,9585 |
|
|
Etape 5 : Evaluer la représentation graphique des P-points et des F-points
En respectant les instructions données plus haut, nous commençons par ajuster les modèles en utilisant tous les P-points et les F-points, respectivement.
Les résultats sont représentés sur le premier graphique à la page des Graphiques diagnostiques du dossier Excel (Figure 2) :
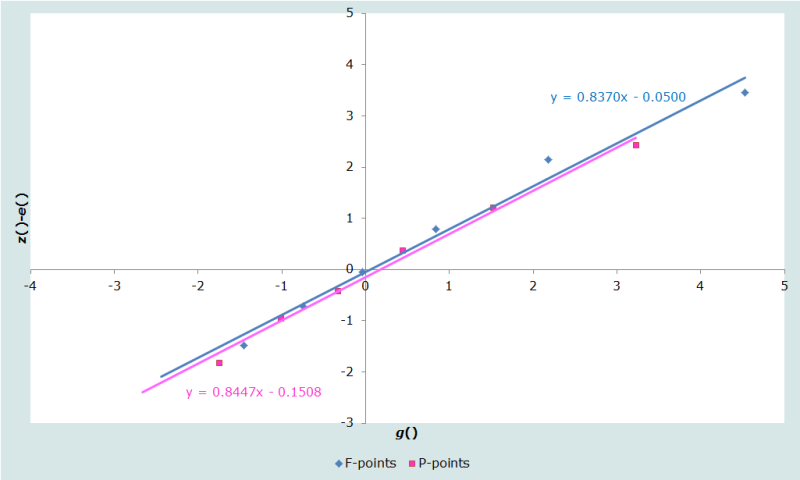
Les deux droites ajustées aux P-points et aux F-points sont très proches l’une au dessus de l’autre, mais aucun des deux ajustements n’est particulièrement bon. Les F-points s’incurvent nettement vers le bas aux âges élevés, ce qui laisse supposer une exagération des âges déclarés, et le fait que les P-points sont juste en dessous des F-points indique un léger recul de la fécondité en cours.
Etape 6 : Ajustement du modèle par sélection des points à utiliser
L’examen du graphique donne à penser que l’ajustement serait meilleur si on omettait les P-points et les F-points du dernier groupe d’âge. On le vérifie en examinant le graphique modifié (Figure 3) :
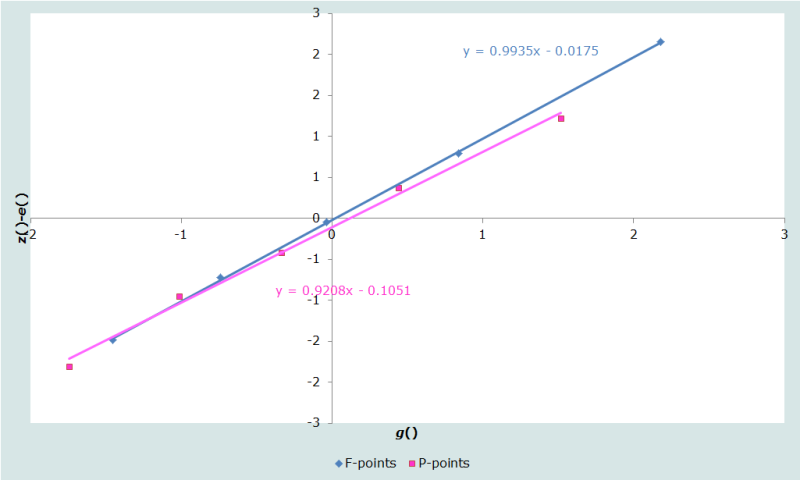
Les droites ne sont plus aussi proches l’une de l’autre et elles ne sont plus parallèles. L’examen visuel suggère que la suppression de l’avant-dernier P-point pourrait permettre à l’ensemble des points restants d’être alignés sur une seule droite (Figure 4).
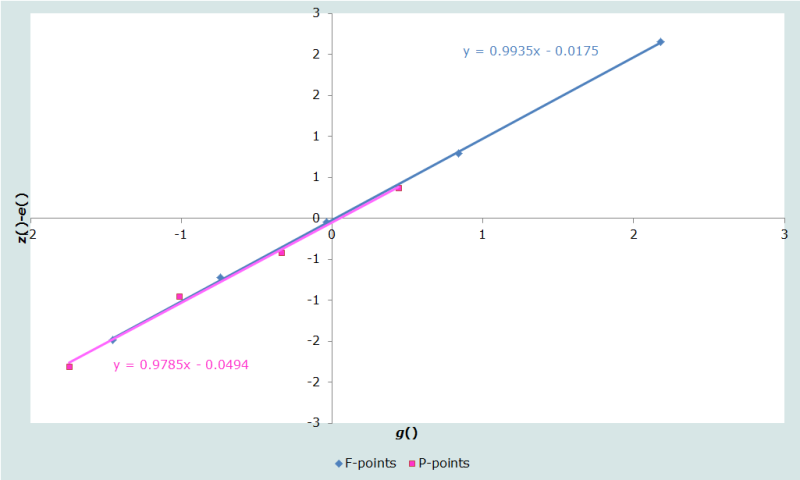
A toutes fins utiles, on peut considérer que ces points s’alignent sur une seule droite, ce qui implique que les parités moyennes et les taux de fécondité qui sous-tendent ces points sont cohérents les uns avec les autres. L’élimination du P-point associé au groupe 35-39 ans permettrait peut-être d’améliorer encore l’ajustement, mais il n’est pas nécessaire de réduire encore le nombre de points inclus dans le modèle pour une très faible amélioration de l’ajustement. L’exclusion de ce P-point entraine un accroissement faible de l’écart quadratique moyen, de 0,044 à 0,045.
Nous pouvons accepter cet ajustement du modèle relationnel de Gompertz. La troisième figure sur la feuille de calcul indique que l’équation de la droite du meilleur ajustement des neuf points restants estz() - e()=0.9936.g() - 0,0272.
A partir de là, la valeur de β est connue directement (0,9936), et celle de alpha est tirée de la formule
où c est la moyenne des tirés du tableau 2 pour les données de fécondité actuelle (puisque les données sont sujettes initialement à un décalage d’une demi-année) et du tableau 4 pour les données de parité.
Etape 7 : Evaluer la qualité des paramètres estimés
Les valeurs estimées de α (-0,0272) et β (0,9936) sont très proches des valeurs standards de 0 et 1. La valeur légèrement négative de α montre que la distribution de la fécondité observée au Malawi en 2008 est un peu plus vieille que le standard et la valeur inférieure à 1 de β suggère que la distribution est légèrement plus étalée que celle du standard.
Etape 8 : Taux de fécondité par âge et indice synthétique de fécondité ajustés
Pour déterminer le niveau global de fécondité, on applique les valeurs ajustées de α et β aux gompits des parités standards (colonne [3] du tableau 4) pour les groupes d’âge dont les P-points ont été inclus dans le modèle, et on calcule les anti-gompits (Tableau 5). En divisant les parités moyennes observées pour un groupe d’âge donné par l’anti-gompit ajusté, on obtient le niveau de fécondité découlant des parités moyennes (colonne [6] du tableau 5), et on déduit une estimation de l’indice synthétique de fécondité, , en faisant la moyenne arithmétique de ces estimations (= 5,9784).
Tableau 5 Calcul de l’indice synthétique de fécondité estimé, Recensement de 2008 au Malawi
Groupe d’âge i | Ys(i) | Y(i) | Anti-gompit | P(i) | Niveau de fécondité déduit |
|---|---|---|---|---|---|
[1] | [2] | [3] | [4] | [5] | [6] |
=α + βYs(i) |
| ||||
1 | -1,0833 | -1,1034 | 0,0491 | 0,283 | 5,7662 |
2 | -0,3124 | -0,3375 | 0,2462 | 1,532 | 6,2218 |
3 | 0,3541 | 0,3246 | 0,4854 | 2,849 | 5,8694 |
4 | 1,0579 | 1,0239 | 0,6982 | 4,185 | 5,9937 |
5 | 1,9561 | 1,9162 | 0,8631 | 5,214 | 6,0407 |
T-chapeau |
|
|
|
| 5,9784 |
Pour obtenir les taux de fécondité par âge associés dans des âges conventionnels, nous appliquons à nouveau α and β, mais cette fois aux gompits de fécondité actuelle, Ys(x), au tableau 3. En prenant les anti-gompits des valeurs ajustées, on obtient une distribution de la fécondité cumulée. Ces proportions sont ensuite amenées au niveau de l’indice synthétique de fécondité, , pour établir la distribution absolue cumulée de la fécondité. En différenciant et en divisant par 5 on obtient les taux de fécondité par âge finaux (Tableau 6).
Tableau 6 Calcul des taux de fécondité corrigés, Malawi, Recensement de 2008
Groupe d’âge (jusqu’à âge x) | Ys(i) | Y(i) | Anti-gompit | Amené au niveau de T chapeau | Taux de fécondité |
|---|---|---|---|---|---|
[1] | [2] | [3] | [4] | [5] | [6] |
=α + β Ys(i) | F(x)=[4]*5.9784 | 5fx-5=(F(x)-F(x-5)) / 5 | |||
15 | -1,7731 | -1,7887 | 0,0025 | 0,0151 | 0,0030 |
20 | -0,6913 | -0,7140 | 0,1298 | 0,7758 | 0,1521 |
25 | 0,0256 | -0,0017 | 0,3673 | 2,1956 | 0,2840 |
30 | 0,7000 | 0,6683 | 0,5989 | 3,5807 | 0,2770 |
35 | 1,4787 | 1,4419 | 0,7894 | 4,7194 | 0,2277 |
40 | 2,6260 | 2,5817 | 0,9271 | 5,5428 | 0,1647 |
45 | 4,8097 | 4,7512 | 0,9914 | 5,9269 | 0,0768 |
50 | 13,8155 | 13,6984 | 1,0000 | 5,9784 | 0,0103 |
Les taux de fécondité par âge figurent à la dernière colonne du tableau 6, pour une fécondité totale (indice synthétique, 15-49 ans) de 5,96 enfants par femme.
Description détaillée de la méthode
Introduction
Le modèle relationnel de Gompertz a été conçu à partir de la méthode du quotient P/F de Brass. Il fonctionne avec les mêmes données de base ; il utilise les données de parité des jeunes femmes pour déterminer le niveau de la fécondité, alors que la distribution de celle-ci est déterminée à partir des déclarations par les femmes de leurs naissances récentes.
Exposé mathématique
Le modèle relationnel de Gompertz pour la fécondité, développé initialement par Brass (1978), est analogue sur bien des points aux modèles logit de mortalité. Le modèle permet de décrire toute distribution de la fécondité par référence à une distribution standard et aux paramètres utilisés pour la transformer afin de produire la distribution cherchée. La transformation utilisée comme base pour établir une relation entre les deux distributions de fécondité est connue comme la transformation de Gompertz. Dans la formulation originelle du modèle, elle est réalisée sur une distribution proportionnelle cumulée, c’est-à-dire où chaque cumulant des parités ou de la fécondité est exprimé en proportion de l’indice synthétique de fécondité (la distribution totalisée). Ce total prend la valeur de un. Les proportions transformées sont intitulées gompits et sont données par
où F(x) est la somme des taux de fécondité par âge cumulés jusqu’à l’âge x et F est l’indice synthétique de fécondité. La même relation vaut pour les parités, en remplaçant F(x) par la parité moyenne par groupe d’âge, et F par la parité cumulée à 50 ans ou +. La transformation de Gompertz ‘étire’ l’axe des âges de sorte que les gompits représentés graphiquement en fonction de l’âge s’alignent à peu près sur une droite. La transformation n’est toutefois pas parfaite, la ligne tendant à s’incurver légèrement aux deux bouts, comme on peut le voir sur la figure 5, où sont représentés les taux de fécondité tirés du standard de Booth (1984).
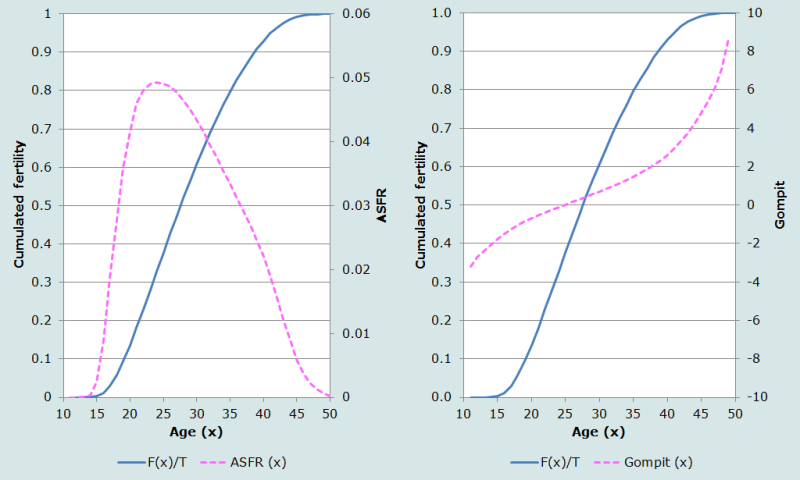
La transformation peut être à la base d’un modèle relationnel parce que les gompits de différentes séries de taux de fécondité en fonction de l’âge tendent à s’écarter de la linéarité de la même manière ; c’est pourquoi la relation entre deux telles séries de gompits est généralement proche de la linéarité. Le recours au modèle dans une forme relationnelle permet une estimation des paramètres du modèle par l’ajustement de droites, ce qui est une procédure simple dont les résultats sont aisés à interpréter.
La relation entre les gompits des cumulants de la fécondité de deux séries de distributions de la fécondité étant à peu près linéaire, on peut relier les gompits d’une distribution observée de la fécondité aux gompits d’une distribution standard fondée sur des données fiables, au moyen d’une relation
où Y(x) est le gompit de la fécondité proportionnée cumulée à l’âge x, et Ys(x) est le gompit des cumulants de la fécondité standard.
Dans cette formulation, α indique dans quelle mesure les âges de fécondité dans la population diffèrent de ceux du standard, les valeurs négatives de α désignant un schéma de fécondité plus âgé. β indique dans quelle mesure l’étalement de la fécondité diffère de celui de la population standard. L’étalement de la distribution est moindre pour les valeurs supérieures à l’unité.
C’est en fait un modèle à trois paramètres. En convertissant les gompits ajustés en estimations de la fécondité cumulée, grâce à la transformation inversée, on obtient une distribution proportionnelle dont la somme est égale à un. Un troisième paramètre est nécessaire pour amener les valeurs ajustées au niveau de fécondité approprié. C’est l’indice synthétique de fécondité – celui-là même qu’on cherche à estimer – mais son estimation à partir des données observées peut ne pas être fiable à cause de déclarations erronées. C’est pourquoi Zaba (1981) a adapté la procédure originelle d’ajustement (qui n’est pas décrite ici). Nous exposons ci-dessous ses contributions et ses extensions de la méthode.
La démarche de Zaba consiste à utiliser les gompits du ratio de deux cumulants successifs de la fécondité, de façon à isoler les paramètres de forme de l’estimation du niveau de fécondité :
Si le cumulant F(x) suit un modèle de Gompertz de paramètres α and β, alors
où est le second terme de l’avant-dernière ligne.
Pour les valeurs de β proches de 1, peut être approximé par un développement en série de Taylor aux environs de β =1:
(3)
A partir de la définition de , .
On peut en outre montrer que
(4)
Zaba (1981) a évalué cette dernière quantité pour différentes valeurs de x, et elle a montré qu’elle était à peu près constante dans l’intervalle 15 ≤ x < 30 ans. (On peut aussi le constater aux tableaux 2-4, où cette quantité a été dérivée). On peut donc remplacer par c, la moyenne arithmétique des quantités dans cet intervalle d’âge, et réécrire l’équation 3
ou
En d’autres termes, il existe une relation linéaire entre et .
Dans un travail ultérieur (Sloggett, Brass, Eldridge et al. 1994), Zaba a redéfini ces termes de la façon suivante :
Terme | Terme redéfini |
|---|---|
| g(x) |
| e(x) |
| z(x) |
D’où la notation révisée
qui implique une relation linéaire entre z – e et g.
En appliquant le même raisonnement que ci-dessus, on peut obtenir la formulation équivalente pour z(i) - e(i) en termes de α, β, c et g(i).
Variantes de la procédure d’ajustement
Dans la version standard du modèle, exposée ici, les données sur la fécondité récente sont utilisées pour déterminer la forme du schéma de fécondité et le niveau de référence est fixé par les points de parité (choisis). D’autres variantes sont possibles qui privilégient une série de données par rapport à l’autre de différentes façons. Nous exposons ici celle qui ne recourt qu’aux données sur la fécondité récente.
La variante F-seulement privilégie les données sur la fécondité récente et les utilise à la fois pour fixer la forme et le niveau de la fécondité dans le modèle. L’analyste ne doit donc utiliser cette variante que lorsqu’il ne dispose pas de données de parité ou qu’il ne souhaite pas qu’elles jouent un rôle dans l’ajustement du modèle. Cette variante se contente de lisser les taux de fécondité observés en utilisant un modèle relationnel de Gompertz.
Il existe une autre extension du modèle relationnel de Gompertz qui ne recourt qu’aux données de parité pour estimer la fécondité à partir des accroissements de parité par cohorte. Il y a aussi une version modifiée du modèle relationnel de Gompertz qui recourt aux données de deux recensements ou enquêtes pour estimer la fécondité entre les enquêtes à partir de ces données.
Construction des standards
Le standard de Booth
L’élaboration du standard de Booth est décrite en détail dans Booth (1984). On retiendra d’une part que le standard est destiné aux populations de fécondité moyenne ou élevée et d’autre part qu’il a été obtenu à partir d’un certain nombre de schémas produits par le modèle de fécondité de Coale-Trussell. Il est donc sujet aux contraintes imposées par ce modèle, lesquelles ne sont généralement pas matérielles.
Le standard utilisé ici n’est pas exactement celui publié par Booth. En premier lieu, le standard de Zaba (1981) diffère légèrement de celui de Booth avant 15 ans pour un meilleur ajustement des situations de fécondité très précoce. Pour en tenir compte, on peut reconstruire entièrement le tableau des coefficients présenté dans Zaba (1981) et dans Sloggett, Brass, Eldridge et al. (1994). Le standard utilisé ici est le même pour les coefficients sans décalage. Quand le décalage est nécessaire, de petites différences apparaissent, qui tiennent au mode d’interpolation du standard originel de Booth. Zaba (1981) a calculé les valeurs pour F(x + 1/2), F(x + 3/2), etc. en interpolant entre les valeurs successives de F(x), F(x + 1), F(x + 2). Mais comme la transformation gompit rend F(x) linéaire, il est plus logique d’interpoler les gompits des F(x), Y(x), par demi-année d’âge et d’établir ensuite les valeurs de F(x + 1/2), F(x + 3/2) etc. en prenant les anti-gompits appropriés.
Construction d’autres standards
Comme on l’a déjà dit, le standard de Booth était conçu pour les pays de fécondité moyenne ou forte. Pour appliquer le modèle relationnel de Gompertz à des pays de basse fécondité ou des pays dont les schémas de fécondité sont originaux, d’autres standards sont nécessaires. Nous expliquons brièvement ici comment procéder.
La démarche nécessite à la base une série de F(x) qui puisse être convertie au moyen d’un gompit en une série de Y(x). On en tire ensuite des valeurs de , et en recourant aux relations établies par les équations 3 et 4. A partir de là, on peut calculer des tableaux de z(), e() et g(). Comme signalé plus haut, les valeurs de sont à peu près constantes, pour un standard donné, entre 15 et 30 ans, aussi la moyenne des trois valeurs (15-19, 20-24, 25-29) donne-t-elle une estimation du terme constant, c.
La construction d’un nouveau standard doit s’appuyer sur une série de taux de fécondité par âge, fs(x), de bonne qualité. En se référant à l’analyse démographique traditionnelle, on peut alors définir les cumulants équivalents :
La fonction f(a) n’étant pas intégrable dans la plupart des cas, il faut il faut recourir à des techniques numériques pour approximer l’intégrale. En utilisant de façon récursive la formule du trapèze composite
on calcule aisément le gompit z(x).
En s’appuyant sur les propriétés d’un développement de Taylor décrit à l’équation 4, on peut définir les composantes de e(x) et g(x) et en déduire des expressions de ces quantités.
Les valeurs de z(i), g(i) et e(i) sont définies de la même façon, en y ajoutant la nécessité d’en tirer les parités constantes associées à F(x). Dans chaque groupe d’âge [x, x+n), les parités sont données par qui peut aussi être évalué en recourant à la formule du trapèze composite.
Autres lectures et références
En plus des textes déjà cités, les travaux sur le modèle relationnel de Gompertz sont peu nombreux. C’est sans doute dû en partie au fait qu’il a été décrit par Booth (1984) peu après la publication du Manuel X, un exposé cohérent du mode d’application du modèle n’apparaissant ensuite que dans le manuel de l’ISAP (Sloggett, Brass, Eldridge et al. 1994). La méthode a été appliquée dans de nombreux cas à travers le monde, mais pas dans la forme décrite ici.
Par exemple, la suite de feuilles de calcul (PASEX) préparée par le US Census Bureau (1997) offre une version simplifiée du modèle, l’utilisateur étant forcé d’ajuster P et F par des droites en utilisant seulement 2 P-points et 2 F-points, ou 3 de chaque, sans beaucoup s’attacher à la cohérence interne des points choisis. C’est la voie adoptée par l’Office Statistique du Malawi dans son analyse des données de fécondité du recensement de 2008. Etant donné la forte cohérence de ces données pour l’ensemble des femmes âgées de moins de 40 ans, les résultats présentés dans ce rapport (indice synthétique de fécondité = 6,0) ne diffèrent guère de ceux présentés plus haut à titre d’exemple. Avec des données de moindre qualité, une telle congruence des résultats de diverses applications ne serait pas assurée.
Booth H. 1980. "The estimation of fertility from incomplete cohort data by means of the transformed Gompertz model." Unpublished PhD thesis, London: University of London.
Booth H. 1984. "Transforming Gompertz' function for fertility analysis: The development of a standard for the relational Gompertz function", Population Studies 38(3):495-506. doi: https://dx.doi.org/10.2307/2174137
Brass W. 1978. The relational Gompertz model of fertility by age of woman. London: Centre for Population Studies, London School of Hygiene and Tropical Medicine.
Sloggett A, W Brass, SM Eldridge, IM Timæus, P Ward and B Zaba (eds). 1994. Estimation of Demographic Parameters from Census Data. Tokyo: Statistical Institute for Asia and the Pacific.
US Census Bureau. 1997. Population Analysis Spreadsheets for Excel. Washington, D.C: US Bureau of the Census. https://www.census.gov/data/software/pas.html Access: 17 Octobre 2024.
Zaba B. 1981. Use of the Relational Gompertz Model in Analysing Fertility Data Collected in Retrospective Surveys. Centre for Population Studies Research Paper 81-2. London: Centre for Population Studies, London School of Hygiene & Tropical Medicine.
- Printer-friendly version
- Log in to post comments