La méthode généralisée de la balance de l’accroissement démographique
Description de la méthode
Kenneth Hill (Hill 1987) a proposé une généralisation de la méthode de Brass de la balance de l’accroissement démographique (Brass growth balance method) faite pour estimer la complétude de l’enregistrement des décès par rapport à une estimation de la population, et qui repose sur l’hypothèse que la population est démographiquement stable. Cette généralisation s’applique au cas où la population n’est plus stable, mais reste fermée aux migrations. Elle peut s’utiliser dans le cas où l’on dispose des données sur les effectifs de population par groupe d’âge à deux recensements, et du nombre de décès par groupe d’âge entre les dates des deux recensements. Avec l’information supplémentaire des deux recensements, il est possible d’estimer les taux de croissance par âge, au lieu de prendre un taux constant comme on le fait dans l’hypothèse d’une population stable. Mais la méthode repose toujours sur les mêmes autres hypothèses : les proportions de décès déclarés et la complétude du recensement sont constants aux âges adultes, et les données déclarées sont précises. De plus, dans sa formulation la plus simple, la méthode repose sur l’hypothèse que la population est fermée aux migrations ; on peut cependant adapter la méthode pour prendre en compte les migrations si on dispose des données correspondantes.
Dans toutes les populations fermées, la relation suivante est vérifiée : , où le taux partiel de natalité, , est défini comme le taux auquel la population atteint l’âge x au sein de la population âgée de x années et plus ; et le taux partiel de mortalité, , est défini comme le taux de mortalité dans la population âgée de x années et plus. Si, dans cette population, les décès sont sous-déclarés dans une même proportion à tous les âges, alors la relation devient : , où est le taux de mortalité déclaré au-delà de l’âge x, et c est la proportion de décès qui sont effectivement déclarés. En pratique, les recensements de population qui servent au calcul de r(x+) peuvent ne pas être complets ; on fera alors l’hypothèse que la sous-déclaration est la même à tous les âges, ce qui permet de trouver c d’après la relation linéaire entre les points donnés par : et . Les taux de mortalité corrigés s’obtiennent alors en divisant les nombres de décès déclarés dans chaque groupe d’âge par c, et en divisant ces nombres par l’estimation de la population au risque. Ceci permet de calculer les taux partiel de natalité, de mortalité et de croissance. De plus, un sous-produit de cette procédure est de permettre de corriger un des deux recensements, dans le cas où l’un des deux est moins complet que l’autre, de manière à ce que les deux soient cohérents, même s’ils ne sont ni l’un ni l’autre parfaitement complets.
Données requises et hypothèses
Tabulation des données nécessaires
- Effectifs de femmes (ou d’hommes), par groupe d’âge de 5 ans, et pour l’intervalle d’âge ouvert A+ (A étant aussi élevé que possible), à deux instants donnés, le plus souvent provenant de deux recensements exhaustifs (voir les mises-en-garde ci-dessous pour le cas où l’on utilise des enquêtes par sondage au lieu des recensements).
- Nombre de décès de femmes (ou d’hommes), par groupe d’âge de 5 ans, et pour l’intervalle d’âge ouvert A+, au cours de la période située entre les deux recensements ou les deux enquêtes.
Hypothèses importantes
- La couverture de chaque recensement est la même à tous les âges.
- La complétude de la déclaration des décès est la même à tous les âges au-delà d’un âge minimal (en général 5 ans ou 15 ans).
- La population est fermée aux migrations. On peut cependant adapter la méthode pour tenir compte des migrations, mais les données précises des effectifs de migrations nettes n’existent que rarement. Pour les populations nationales, les migrations nettes sont souvent suffisamment faibles pour être négligées. Mais dans les situations où les migrations sont importantes, il convient de les prendre en compte pour interpréter les résultats et décider de l’estimation finale de la complétude.
Travaux préparatoires et recherches préliminaires
Avant d’appliquer la méthode, il convient d’analyser la qualité des données, au moins en ce qui concerne les dimensions suivantes :
- structure par âge de la population;
- structure par sexe de la population;
- structure par âge des décès; et
- structure par sexe des décès.
Lorsque les décès déclarés se rapportent à une période autre que celle comprise entre les deux recensements, il convient d’estimer les nombre de décès qui auraient dû être déclarés pendant la période intercensitaire. Ainsi, lorsqu’on dispose des décès déclarés à l’état civil par année de calendrier, l’ajustement consistera à répartir proportionnellement les décès de l’année du premier recensement et ceux de l’année du second recensement. Si l’on dispose des décès déclarés par les ménages au cours des 12 derniers mois avant chaque recensement, il faudra estimer le nombre de décès au cours de la période intercensitaire par interpolation entre les deux estimations précédentes (voir la feuille de calcul : AM_Estimating deaths.xlsx).
Précautions et mises en garde
Pour appliquer cette méthode, les analystes devront faire attention tout particulièrement aux points suivants.
Les processus d’interprétation et d’estimation finale doivent tenir compte de la source des données sur les décès (décès déclarés à l’état civil, décès déclarés par les ménages lors d’un recensement, décès enregistrés dans les hôpitaux), comme cela est expliqué ci-dessous. Mais les biais associés aux sources de données tendent à avoir moins d’impact sur l’estimation de la complétude obtenue par la méthode de la balance de l’accroissement démographique, que par la méthode de l’extinction des cohortes synthétiques.
La question des migrations devient plus importante lorsqu’on applique la méthode à des zones géographiques régionales.
Le choix de l’intervalle d’âge utilisé pour ajuster la ligne droite aux taux partiels de natalité et de mortalité, qui détermine l’estimation de la complétude, est important. Les problèmes en la matière sont les suivants : le meilleur choix pour l’âge de début de l’intervalle ouvert lorsqu’on sait que l’âge est exagéré ; comment traiter les points qui sont situés au-dessus de la droite de régression aux âges élevés, du fait de la baisse de la complétude ; celle-ci peut être due aux migrations associées à la retraite de personnes qui migrent de l’urbain vers le rural où l’enregistrement des décès est moins complet. Enfin, il faut décider s’il convient d’exclure les âges en-dessous de 30 ou 35 ans lorsqu’on ne peut pas corriger l’effet des migrations.
Si la complétude semble être inférieure à 60%, alors le degré d’incertitude devient grand, et ce point doit être pris en compte pour interpréter les résultats.
Dans la situation où les données sur la population et les décès des ménages sont collectées lors d’un recensement unique, il est tentant de chercher à utiliser des données d’une enquête par sondage pour avoir une répartition par âge de la population à une autre date, antérieure ou postérieure, de manière à pouvoir utiliser la méthode. Mais, pour des raisons qui ne sont pas claires et qui n’ont pas fait l’objet de recherches approfondies, une telle combinaison de sources de données très différentes donne rarement des résultats satisfaisants.
Application de la méthode
D’un point de vue purement technique, on pourrait appliquer cette méthode à des données présentées par année d’âge, mais ce type de données est sujet à de fortes erreurs sur l’âge, si bien que, en pratique, on travaille le plus souvent avec des données présentées par groupe d’âge de 5 ans. Comme la plupart des données disponibles sont publiées selon ce format, la feuille de calcul correspondante est organisée pour travailler avec des groupes d’âge quinquennaux classiques. Il faut remarquer que John Blacker (Blacker 1988) a montré que ces groupes d’âge classiques sont sensibles aux préférences pour les chiffres ronds ; dans ce cas on pourra adapter la méthode pour travailler avec des groupes d’âge quinquennaux différents, centrés sur les chiffres qui font l’objet de l’attraction (12-17, 18-21 etc.), plutôt qu’avec des groupes d’âge commençant par ces chiffres (15-19, 20-24, etc.).
Etape 1: Lorsque ce nombre n’est pas immédiatement disponible, estimer le nombre de décès déclarés au cours de la période entre les deux estimations de population
Dans le cas où l’on dispose de données de l’état civil par année de calendrier, l’ajustement consiste à répartir proportionnellement les décès de la première et de la dernière année. On les répartit proportionnellement à la fraction de l’année couverte après le premier recensement et avant le second recensement. Sauf si la distribution des décès par âge change très rapidement au cours de l’année, cette approximation n’aura pas d’effet notable sur les résultats.
Dans le cas où l’on ne dispose pas des décès entre les deux enquêtes, mais si l’intervalle tombe entre deux périodes pour lesquelles on a de telles données (par exemple dans le cas où chaque recensement inclut la question sur les décès des douze derniers mois dans le ménage), alors on peut utiliser la feuille de calcul suivante : AM_Estimating deaths. Cette feuille de calcul permet d’estimer le nombre de décès entre deux instants donnés d’après les décès qui se sont produits au-cours de deux périodes les encadrant. Pour utiliser cette feuille de calcul, on a besoin du nombre de décès répartis par groupes d’âge quinquennaux pour les deux périodes, les dates de début et de fin de chaque période, ainsi que les dates de début et de fin de la période au cours de laquelle on veut estimer le nombre de décès.
Etape 2: Cumuler la population, les décès et les migrants vers les plus jeunes âges
Pour calculer les taux partiels de natalité, mortalité (et migration), on doit cumuler les effectifs de population, le nombre de décès (et le nombre de migrations nettes), pour les âges au-delà de x. Ainsi, dans le cas de la population, on utilise la formule suivante :
où A désigne l’âge au début du groupe d’âge ouvert. On utilise des formules équivalentes pour calculer les décès cumulés au-delà de l’âge x, soit D(x+). On peut faire de même pour les migrations nettes (même si cela est peu probable), et cumuler leur nombre au-delà de l’âge x, soit NM(x+). Lorsque le nombre de migrants est inconnu, on laisse cette colonne en blanc (ou bien on fixe les effectifs à zéro), et la méthode s’utilise en prenant en compte cette omission, comme cela est expliqué plus loin.
Etape 3: Calcul des personnes-années vécues, PYL(x+)
Pour calculer les taux partiels de natalité et de mortalité (ainsi que les taux partiels de migration nette s’ils sont disponibles), on doit calculer les personnes-années vécues au risque. On utilise pour cela la formule suivante :
où t1 est la date du premier recensement, et t2 la date du second recensement.
Etape 4: Calcul du nombre de personnes qui atteignent leur x-ème anniversaire, N(x)
Le nombre de personnes qui atteignent leur x-ème anniversaire (c’est à dire ceux arrivent, ou sont ‘nés’, dans le groupe d’âge x+) dans la population se calcule comme la moyenne géométrique des effectifs de la cohorte au temps t1 et t2 divisé par 5, multiplié par la durée de la période entre les deux recensements, exprimée en années, selon la formule suivante :
Etape 5 : Calcul des taux partiels de natalité et de mortalité, b(x+) et d(x+), et de croissance r(x+), corrigés des migrations, i(x+)
Les taux partiels de natalité et de mortalité se calculent selon les formules suivantes :
Alors, le taux partiel de croissance, moins le taux partiel de migration, se calcule selon la formule suivante:
Etape 6 : Représentation graphique de b(x+) - r(x+) + nm(x+) en fonction de d(x+), et examen visuel pour décider de l’intervalle d’âge sur lequel on ajustera une droite
On commence en prenant pour âge minimal l’âge de 50 ans, et pour âge maximal A-1, où A est l’âge du début de l’intervalle ouvert. On examine ensuite le graphique, et on décide de l’intervalle d’âge sur lequel on ajustera une droite. Lorsque l’exagération des âges au décès est plus forte que celle des âges des survivants dans la population, les points situés à droite du graphique (qui représentent les âges élevés) vont tendre à baisser progressivement avec l’âge en-dessous de la droite. Ceci indique qu’il faut rechercher un âge maximal plus faible, de proche en proche tous les 5 ans, jusqu’à ce que l’effet soit éliminé. De plus, si la valeur des résidus est trop forte aux âges extrêmes (par exemple s’ils excèdent 1%), alors l’âge maximal devra être abaissé, pour éviter que ces points erronés influencent la pente de la droite ajustée. Mais si l’exagération de l’âge est la même pour la population et pour les décès, alors ceci n’aura pas d’influence sur la pente ni sur l’estimation de la complétude de la déclaration des décès ; par contre, les taux de mortalité par âge seront sous-estimés à ces âges élevés.
Lorsque les points placés sur le graphique correspondants aux âges jeunes (c’est-à-dire la partie gauche du graphique), surtout aux âges entre 15 et 30 ans, dévient notablement de la ligne droite, et si l’on n’a pas introduit de données sur les migrations, ceci indique probablement qu’il y a un niveau important de migrations (sauf s’il y a une couverture du recensement différentielle selon l’âge). Dans ce cas, il convient d’augmenter l’âge minimal du début de l’intervalle utilisé pour ajuster la droite à 30 ou 35 ans, selon celui qui produit le meilleur ajustement aux données.
Etape 7 : Ajustement d’une droite, et estimation de la complétude (c)
Pour estimer la complétude de l’enregistrement des décès par rapport à la population, on commence par tracer un graphique représentant les points d’abscisse : d(x+) et d’ordonnées : b(x+) – r(x+) + i(x+). On calcule les coefficients de la droite liant les deux séries de points par régression orthogonale, selon la formule suivante :
et
où b représente la pente de la droite, et a l’ordonnée à l’origine. La série des ordonnées yi représente les points: b(x+) - r(x+) + i(x+), la série des abscisses xi représente les points d(x+), et les variables et représentent, respectivement, les moyennes des deux séries.
Lorsque l’on a tracé la droite de régression, on observe la position des points par rapport à la droite, ainsi que les résidus, de manière à décider quel est le meilleur intervalle d’âge à garder pour calculer la complétude de l’enregistrement des décès. La manière de le faire est discutée plus en détail plus loin, mais on considère qu’il faut exclure les points dont les résidus sont supérieurs à 1% en valeur absolue. Après exclusion des points aberrants, une nouvelle droite est ajustée, et on calcule de nouvelles valeurs de a et b. En règle générale, on recommande de ne pas terminer à un âge qui se termine par zéro dans les populations qui font preuve d’une forte attraction des chiffres ronds.
On calcule alors la complétude de l’enregistrement des décès, c, d’après les valeurs de a et de b, comme suit. Comme:
et
on fait alors l’hypothèse que le maximum de k1 et k2 = 1. Si , on suppose que k2 = 1, et donc
et si , on suppose que k1 = 1, et donc :
et
.
Etape 8 : Estimer les taux de mortalité après correction de la complétude des décès déclarés
Afin de calculer les taux de mortalité corrigés, il convient au préalable de corriger les recensements de population en tenant compte de leurs couvertures relatives. Ceci se fait en divisant les effectifs du premier recensement par k1 et les effectifs du second recensement par k2.
Ensuite, on doit corriger les nombres de décès du sous-enregistrement, en divisant les nombres de décès déclarés par l’estimation de la complétude c.
Les personnes-années vécues corrigées, PYLa(x,5), se calculent de la même manière qu’avant, mais en utilisant les effectifs corrigés du sous-enregistrement relatif des recensements, soit :
Ensuite, on calcule les taux de mortalité corrigés de tous les biais (complétude de l’enregistrement des décès et couverture des recensements) en divisant les effectifs corrigés des décès et des personnes-années vécues, soit:
Remarquons que, d’un point de vue purement technique, on pourrait omettre le coefficient d’ajustement k1/k2 et obtenir les mêmes valeurs pour les taux de mortalité corrigés (puisqu’on fait la même correction au numérateur et au dénominateur). Mais dans ce cas, l’estimation de la complétude correspondrait à la moyenne des populations recensées et ignorerait le fait qu’ils ont des couvertures différentes.
Etape 9 : Lissage à l’aide d’une table-type et d’un système relationnel logit
Lorsque les taux de mortalité par âge sont erratiques, on peut les lisser à l’aide d’un modèle. Ceci peut se faire à l’aide du système relationnel logit de Brass et d’une table-type du même sexe que l’on considère avoir le même schéma par âge que celui qui s’applique à la population étudiée.
Le classeur Excel correspondant à cette méthode comporte une feuille de calcul qui permet de produire des taux de mortalité lissés à l’aide d’un système relationnel logit et d’une table type de mortalité. L’utilisateur a le choix entre un standard du modèle Général de la famille des tables-type des Nations Unies, ou l’un des quatre modèles régionaux des tables-type de Princeton. La transformation logit de ces tables-type de mortalité, ainsi qu’une table-type d’une population affectée par l’épidémie de sida (Timæus 2007) sont donnés dans la feuille de calcul intitulée Modèles. Cette feuille de calcul permet aussi à l’utilisateur de choisir comme standard une autre table de mortalité sous forme de logit, s’il y a de bonnes raisons de penser que cette table a un schéma par âge similaire à celui de la population étudiée.
Pour ajuster le modèle logit, on calcule d’abord les quotients quinquennaux de mortalité, 5qx, d’après les taux corrigés de mortalité, 5mx, selon la formule :
Puis on calcule la table de mortalité de proche en proche, en partant d’une racine l5 = 1 , selon la formule de récurrence suivante :
Les coefficients, α et β , du système relationnel logit se calculent par régression linéaire, comme:
où la fonction logit est définie comme: et où l’exposant s désigne les valeurs de la table de mortalité de référence (le standard).
La table de mortalité lissée se calcule ensuite en appliquant les coefficients α and β comme suit :
et
Les taux de mortalité lissés se calculent dans la table de mortalité comme suit:
et
où
soit :
où ω désigne l’âge au-delà duquel il ne reste plus de survivants.
Exemple
Cet exemple utilise les données de la population masculine d’Afrique du Sud, recueillies au recensement de 2001 et à l’enquête de communauté de 2007, et les données des décès enregistrés à l’état civil au cours des années de 2001 à 2007. Le solde migratoire est estimé d’après le changement du nombre de personnes nées à l’étranger repérées aux deux enquêtes, moins une estimation du nombre de sud-africains qui ont émigré à l’étranger entre les deux enquêtes. Cet exemple est détaillé dans le classeur Excel intitulé : AM_GGB_South Africa_males.
Etape 1: Calculer le nombre de décès déclarés au cours de la période située entre les deux estimations de population
Les décès déclarés au cours des années 2001 à 2007 pour les hommes sud-africains apparaissent dans le tableau 1.
Tableau 1 : Calcul des décès déclarés entre les deux dates des recensements, sud-africains de sexe masculin, 2001-2007
Age | 2001 | 2002–2006 | 2007 | Total entre les deux recensements |
|---|---|---|---|---|
| 0–4 | 29 005 | 186 346 | 40 314 | 197 912 |
| 5–9 | 2 118 | 14 733 | 2 854 | 15 566 |
| 10–14 | 1 745 | 10 535 | 2 233 | 11 207 |
| 15–19 | 4 470 | 23 857 | 4 860 | 25 473 |
| 20–24 | 8 931 | 51 588 | 10 875 | 54 960 |
| 25–29 | 16 834 | 96 705 | 18 405 | 102 802 |
| 30–34 | 20 892 | 137 355 | 28 245 | 145 588 |
| 35–39 | 21 068 | 137 502 | 29 258 | 145 900 |
| 40–44 | 19 322 | 128 217 | 26 973 | 135 936 |
| 45–49 | 17 881 | 113 891 | 24 761 | 121 010 |
| 50–54 | 16 883 | 104 508 | 22 790 | 111 157 |
| 55–59 | 14 544 | 90 919 | 21 317 | 96 854 |
| 60–64 | 15 097 | 84 351 | 17 410 | 89 930 |
| 65–69 | 13 011 | 77 680 | 17 878 | 82 843 |
| 70–74 | 14 035 | 68 147 | 13 771 | 73 036 |
| 75–79 | 10 846 | 59 859 | 12 534 | 63 871 |
| 80–84 | 9 161 | 44 986 | 8 872 | 48 163 |
| 85+ | 7 602 | 43 233 | 10 009 | 46 196 |
La date de référence du recensement de 2001 était la nuit du 9 au 10 octobre 2001. L’enquête de communauté se déroula sur plusieurs semaines en février, et on prendra comme date de référence la nuit du 14 au 15 février 2007. Donc, en supposant que les décès sont répartis uniformément au cours de l’année, on peut répartir proportionnellement les décès de 2001 et de 2007, et les ajouter au total des années 2002 à 2006. Ceci donne le total des décès qui se sont produits entre les deux dates de recensement. Par exemple, pour le groupe d’âge 20-24 ans, le nombre se calcule comme suit :
Etape 2: Cumul de la population, des décès et des migrants vers le bas
On cumule alors les effectifs de la population, des décès et des migrants, vers le bas, de l’âge x jusqu’au dernier groupe d’âge (tableau 2).
Tableau 2 : Calcul des effectifs cumulés de population, décès et migrants, Afrique du sud, sexe masculin, 2001-2007
| Age | 5Nx(t1) | 5Nx(t2) | 5Dx | 5NMx | P1(x+) | P2(x+) | D(x+) | NM(x+) |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 223 006 | 2 505 744 | 197 912 | 10 605 | 21 434 045 | 23 348 679 | 1 568 404 | 128 946 |
| 5 | 2 425 066 | 2 560 642 | 15 566 | 2 848 | 19 211 039 | 20 842 935 | 1 370 492 | 118 341 |
| 10 | 2 518 985 | 2 452 339 | 11 207 | 5 153 | 16 785 973 | 18 282 293 | 1 354 926 | 115 492 |
| 15 | 2 453 156 | 2 553 293 | 25 473 | 16 574 | 14 266 988 | 15 829 955 | 1 343 719 | 110 339 |
| 20 | 2 099 417 | 2 362 519 | 54 960 | 14 803 | 11 813 832 | 13 276 662 | 1 318 246 | 93 766 |
| 25 | 1 899 275 | 2 033 165 | 102 802 | 4 714 | 9 714 415 | 10 914 143 | 1 263 286 | 78 963 |
| 30 | 1 594 624 | 1 875 483 | 145 588 | 13 331 | 7 815 140 | 8 880 977 | 1 160 484 | 74 249 |
| 35 | 1 441 657 | 1 548 185 | 145 900 | 9 693 | 6 220 516 | 7 005 495 | 1 014 896 | 60 918 |
| 40 | 1 233 813 | 1 306 900 | 135 936 | 7 464 | 4 778 859 | 5 457 310 | 868 996 | 51 225 |
| 45 | 967 744 | 1 104 294 | 121 010 | 8 719 | 3 545 046 | 4 150 410 | 733 060 | 43 761 |
| 50 | 769 627 | 888 042 | 111 157 | 9 413 | 2 577 302 | 3 046 116 | 612 050 | 35 042 |
| 55 | 552 402 | 708 812 | 96 854 | 4 640 | 1 807 675 | 2 158 074 | 500 893 | 25 629 |
| 60 | 444 592 | 491 871 | 89 930 | 5 081 | 1 255 273 | 1 449 261 | 404 039 | 20 989 |
| 65 | 304 835 | 394 305 | 82 843 | 4 922 | 810 681 | 957 391 | 314 108 | 15 908 |
| 70 | 232 604 | 241 976 | 73 036 | 4 334 | 505 846 | 563 086 | 231 266 | 10 986 |
| 75 | 136 466 | 163 112 | 63 871 | 2 980 | 273 242 | 321 110 | 158 229 | 6 652 |
| 80 | 90 856 | 87 698 | 48 163 | 1 662 | 136 776 | 157 998 | 94 359 | 3 672 |
| 85 | 45 920 | 70 299 | 46 196 | 2 009 | 45 920 | 70 299 | 46 196 | 2 009 |
Etape 3: Calcul des personnes-années vécues, PYL(x+)
Le calcul des personnes-années vécues nécessite de connaître d’intervalle de temps entre les deux recensements. Ceci peut se calculer à l’aide de la fonction YEARFRAC dans Excel d’après des dates de référence des deux recensements (soit 5,3541 années). Le décompte des jours entre les deux dates divisé par 365 (soit 5,3507 années) n’est pas identique, mais cette différence a un impact négligeable sur l’estimation de la complétude.
Les personnes-années vécues apparaissent en colonne 2 du tableau 3, et se calculent d’après les effectifs cumulés de population qui figurent en colonne 2 et 3 du tableau 2. Par exemple, pour l’âge de 20 ans, le calcul est le suivant :
Tableau 3 : Calcul des effectifs cumulés de la population, des décès et des migrants, Afrique du sud, sexe masculin, 2001-2007
| Age | PYL(x+) | N(x) | b(x+) | r(x+)-i(x+) | d(x+) = X | b(x+)-r(x+) +i(x+) = Y | a+bx | Résidus y-(a+bx) |
|---|---|---|---|---|---|---|---|---|
| 0 | 119 775 275 | #N/A | 0,00000 | -0,0047 | ||||
| 5 | 107 136 837 | 2 554 810 | 0,02385 | 0,01413 | 0,01279 | 0,00972 | 0,0093 | 0,0004 |
| 10 | 93 793 458 | 2 611 355 | 0,02784 | 0,01472 | 0,01445 | 0,01312 | 0,0111 | 0,0020 |
| 15 | 80 461 835 | 2 715 670 | 0,03375 | 0,01805 | 0,01670 | 0,01570 | 0,0135 | 0,0022 |
| 20 | 67 053 861 | 2 577 889 | 0,03845 | 0,02042 | 0,01966 | 0,01803 | 0,0168 | 0,0013 |
| 25 | 55 129 886 | 2 212 329 | 0,04013 | 0,02033 | 0,02291 | 0,01980 | 0,0203 | -0,0005 |
| 30 | 44 604 915 | 2 020 991 | 0,04531 | 0,02223 | 0,02602 | 0,02308 | 0,0237 | -0,0006 |
| 35 | 35 344 071 | 1 682 498 | 0,04760 | 0,02049 | 0,02871 | 0,02712 | 0,0266 | 0,0005 |
| 40 | 27 342 320 | 1 469 826 | 0,05376 | 0,02294 | 0,03178 | 0,03082 | 0,0300 | 0,0008 |
| 45 | 20 537 160 | 1 249 916 | 0,06086 | 0,02735 | 0,03569 | 0,03352 | 0,0343 | -0,0007 |
| 50 | 15 001 678 | 992 684 | 0,06617 | 0,02891 | 0,04080 | 0,03726 | 0,0398 | -0,0026 |
| 55 | 10 574 924 | 790 897 | 0,07479 | 0,03071 | 0,04737 | 0,04408 | 0,0470 | -0,0029 |
| 60 | 7 221 483 | 558 171 | 0,07729 | 0,02396 | 0,05595 | 0,05334 | 0,0564 | -0,0030 |
| 65 | 4 716 866 | 448 343 | 0,09505 | 0,02773 | 0,06659 | 0,06732 | 0,0680 | -0,0006 |
| 70 | 2 857 463 | 290 826 | 0,10178 | 0,01619 | 0,08093 | 0,08559 | 0,0836 | 0,0020 |
| 75 | 1 585 932 | 208 577 | 0,13152 | 0,02599 | 0,09977 | 0,10553 | 0,1041 | 0,0014 |
| 80 | 787 071 | 117 144 | 0,14884 | 0,02230 | 0,11989 | 0,12654 | 0,1261 | 0,0005 |
| 85 | 304 201 |
Etape 4 : Calcul du nombre de personnes qui atteignent l’âge x dans la population, N(x)
Les nombres de personnes qui atteignent l’âge x figurent en colonne 3 du tableau 3. Par exemple, le nombre de personnes qui atteignent l’âge de 20 ans se calcule d’après les effectifs de population qui figurent en colonne 2 et 3 du tableau 1, comme suit :
Etape 5 : Calcul des taux partiels de natalité et de mortalité, b(x+) et d(x+), et du taux partiel de croissance r(x+) après correction des migrations, i(x+)
Les taux partiels de natalité et de mortalité figurant en colonne 4 et 6 du tableau 3. Par exemple, pour l’âge de 20 ans, les taux partiels de natalité et de mortalité se calculent à partir des naissances partielles (colonne 3 du tableau 3) et des décès partiels (colonne 8 du tableau 2) comme suit :
et
Le taux partiel de croissance, diminué du taux partiel de migration nette, figure en colonne 5 du tableau 3. Par exemple, pour l’âge de 20 ans, il se calcule à partir des populations cumulées qui figurent en colonne 2 et 3 du tableau 3, et des migrations nettes cumulées qui figurent dans la dernière colonne du tableau 2, comme suit :
Etape 6: Représentation graphique de b(x+) - r(x+) + i(x+) en fonction de d(x+), et analyse de la figure pour décider quel intervalle d’âges choisir pour ajuster la droite
Pour tracer le graphique et ajuster la droite liant tous les points, on commence par fixer l’âge minimal à 5 ans, et l’âge maximal à 84 ans (car, dans cet exemple, l’intervalle d’âge ouvert est de 85 ans et plus). La figure 1 donne le graphique des points de coordonnées : b(x+) - r(x+) + i(x+) et d(x+).
L’analyse visuelle des points de ce graphique (figure 1) montre que ceux-ci sont assez bien alignés, et assez proches de la ligne de régression, ce qui indique que l’essentiel des migrations a bien été pris en compte. Dans ce cas, il n’y a pas de raison de changer l’intervalle d’âge sur lequel la droite est ajustée. Et donc, comme on peut s’y attendre, augmenter l’âge minimal n’aurait que peu d’effet sur l’estimation de la complétude, qui est ici de 91%. De même, l’estimation de la complétude ne serait guère affectée en diminuant l’âge maximal, c’est-à-dire en excluant le dernier ou les deux derniers points, même si les résultats sont un peu affectés par une baisse de la complétude aux âges élevés (voir l’application de la méthode d’extinction des cohortes synthétiques). Par contre, éliminer d’autres points conduirait à augmenter la complétude et atteindre des niveaux irréalistes, ce qui suggère un problème de qualité des données (probablement les données de population).
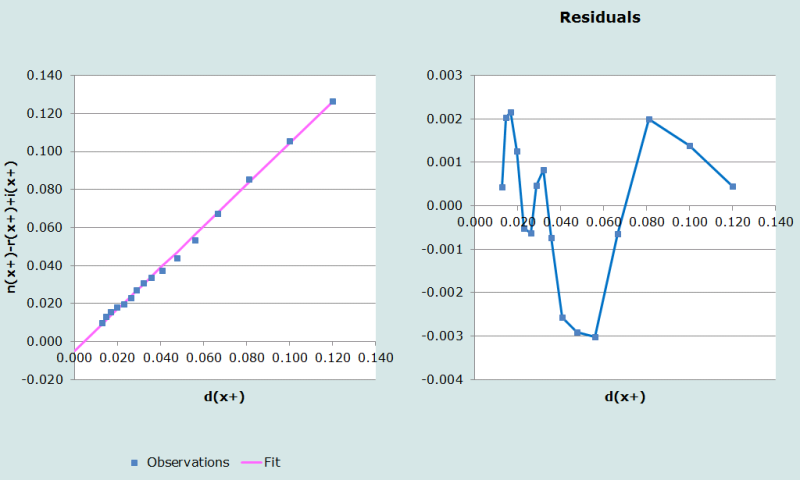
Etape 7: Ajustement de la droite, et estimation de la complétude, c
Les coefficients de la droite ajustant au mieux les points de la Figure 1 se calculent comme suit:
et la couverture relative des deux recensements se calcule comme suit:
Comme k2>k1 on considère que k2 = 1 et donc que k1 = 0,9753 (c’est-à-dire que le décompte du premier recensement est sous-estimé de 2,5% par rapport au second).
La complétude de la déclaration des décès, c, est estimée à 91% (relativement au décompte de l’enquête de 2007), et se calcule comme suit :
Etape 8: Calcul des taux de mortalité corrigés de la sous-déclaration des décès
On corrige d’abord la population au premier recensement, en divisant la population recensée, qui figure en colonne 2 du tableau 2, par k1. Par exemple, pour l’âge de 20 ans, la population corrigée se calcule comme :
La population corrigée au second recensement se calcule de même, comme la population recensée, qui figure en colonne 3 du tableau 2, divisée par by k2. Comme, par hypothèse, on a pris k2 = 1, ces nombres sont donc les mêmes que ceux qui figurent en colonne 3 du tableau 2.
Ensuite, les décès sont corrigés pour tenir compte de la sous-déclaration, en divisant les nombres de décès déclarés dans chaque groupe d’âge, qui figurent en colonne 4 du tableau 2, par l’estimation de la complétude. Ces nombres figurent en colonne 4 du tableau 4. Par exemple, pour l’âge de 20 ans, le nombre se calcule à partir du nombre de décès déclarés : 54 960 décès, comme suit :
Les personnes-années vécues corrigées (colonne 5 du tableau 4) se calculent comme la moyenne géométrique des populations qui figurent en colonne 2 et 3 du tableau 4, multipliées par la durée (en années) de la période intercensitaire, qui est de 5,3541 années. Par exemple, pour l’âge de 20 ans, cela donne :
Les taux de mortalité corrigés du sous-enregistrement des décès (colonne 6 du tableau 4) se calculent en divisant les décès corrigés par les personnes-années vécues corrigées. Par exemple, pour le groupe d’âge de 20-24 ans, le taux de mortalité corrigé se calcule comme suit :
Table 4 : Calcul des taux de mortalité corrigés, Afrique du Sud, sexe masculin, 2001-2007
| Age | Valeurs corrigées du sous-enregistrement | ||||
|---|---|---|---|---|---|
| 5Nx(t1) | 5Nx(t2) | 5Dx | PYL(x,5) | 5mx | |
0 |
|
|
|
|
|
5 | 2 486 532 | 2 560 642 | 17 193 | 13 510 001 | 0,0013 |
10 | 2 582 831 | 2 452 339 | 12 378 | 13 474 797 | 0,0009 |
15 | 2 515 334 | 2 553 293 | 28 134 | 13 568 508 | 0,0021 |
20 | 2 152 629 | 2 362 519 | 60 701 | 12 074 140 | 0,0050 |
25 | 1 947 414 | 2 033 165 | 113 541 | 10 653 675 | 0,0107 |
30 | 1 635 041 | 1 875 483 | 160 796 | 9 375 725 | 0,0172 |
35 | 1 478 197 | 1 548 185 | 161 141 | 8 099 564 | 0,0199 |
40 | 1 265 085 | 1 306 900 | 150 136 | 6 884 383 | 0,0218 |
45 | 992 273 | 1 104 294 | 133 651 | 5 604 563 | 0,0238 |
50 | 789 134 | 888 042 | 122 768 | 4 482 045 | 0,0274 |
55 | 566 403 | 708 812 | 106 972 | 3 392 442 | 0,0315 |
60 | 455 861 | 491 871 | 99 325 | 2 535 277 | 0,0392 |
65 | 312 561 | 394 305 | 91 497 | 1 879 609 | 0,0487 |
70 | 238 500 | 241 976 | 80 666 | 1 286 217 | 0,0627 |
75 | 139 925 | 163 112 | 70 543 | 808 863 | 0,0872 |
80 | 93 159 | 87 698 | 53 194 | 483 940 | 0,1099 |
85 | 47 084 | 70 299 | 51 021 | 308 032 | 0,1656 |
Etape 9: Lissage en utilisant une table-type et un système relationnel logit
Les quotients quinquennaux de mortalité, corrigés du sous-enregistrement, qui figurent en colonne 2 du tableau 5, se calculent à partir des taux de mortalité corrigés, qui figuraient en colonne 6 du tableau 4. Par exemple, la probabilité pour un homme de décéder entre 20 et 25 ans, se calcule comme suit :
Les survivants de la table de mortalité à l’âge x+5 se calculent à partir des survivants à l’âge x à partir des quotients quinquennaux, et figurent en colonne 3 du tableau 5. Par exemple, la proportion de survivants à l’âge de 25 ans se calcule comme suit :
Tableau 5 : Calcul des taux de mortalité lissés à l’aide d’une table-type et d’un système relationnel logit, Afrique du sud, sexe masculin, 2001-2007
Age | 5qx | lx/l5 |
| Sida Cdn. | Logit | Logit | Surviv. | T(x) | Taux |
|---|---|---|---|---|---|---|---|---|---|
0 | |||||||||
5 | 0,0063 | 1 | 1,0000 | 1 | 50,699 | 0,0032 | |||
10 | 0,0046 | 0,9937 | -2,5270 | 0,9785 | -1,9081 | -2,0551 | 0,9839 | 45,739 | 0,0030 |
15 | 0,0103 | 0,9891 | -2,2542 | 0,9632 | -1,6326 | -1,7292 | 0,9695 | 40,856 | 0,0025 |
20 | 0,0248 | 0,9789 | -1,9186 | 0,9512 | -1,4853 | -1,5550 | 0,9573 | 36,039 | 0,0043 |
25 | 0,0519 | 0,9546 | -1,5229 | 0,9324 | -1,3120 | -1,3500 | 0,9370 | 31,303 | 0,0090 |
30 | 0,0822 | 0,9051 | -1,1273 | 0,8969 | -1,0818 | -1,0777 | 0,8962 | 26,722 | 0,0159 |
35 | 0,0948 | 0,8306 | -0,7951 | 0,8420 | -0,8365 | -0,7875 | 0,8285 | 22,415 | 0,0206 |
40 | 0,1034 | 0,7519 | -0,5544 | 0,7794 | -0,6311 | -0,5446 | 0,7482 | 18,482 | 0,0241 |
45 | 0,1125 | 0,6742 | -0,3636 | 0,7148 | -0,4593 | -0,3414 | 0,6644 | 14,964 | 0,0244 |
50 | 0,1282 | 0,5983 | -0,1992 | 0,6560 | -0,3228 | -0,1799 | 0,5890 | 11,848 | 0,0234 |
55 | 0,1461 | 0,5216 | -0,0433 | 0,6048 | -0,2127 | -0,0497 | 0,5248 | 9,084 | 0,0258 |
60 | 0,1784 | 0,4454 | 0,1097 | 0,5530 | -0,1064 | 0,0760 | 0,4621 | 6,640 | 0,0337 |
65 | 0,2170 | 0,3659 | 0,2749 | 0,4918 | 0,0163 | 0,2212 | 0,3912 | 4,530 | 0,0503 |
70 | 0,2711 | 0,2865 | 0,4562 | 0,4119 | 0,1781 | 0,4125 | 0,3047 | 2,814 | 0,0717 |
75 | 0,3580 | 0,2089 | 0,6659 | 0,3178 | 0,3819 | 0,6536 | 0,2130 | 1,542 | 0,1008 |
80 | 0,4311 | 0,1341 | 0,9327 | 0,2173 | 0,6408 | 0,9598 | 0,1279 | 0,708 | 0,1470 |
85 | #N/A | 0,0763 | 1,2470 | 0,1201 | 0,9959 | 1,3799 | 0,0595 | 0,252 | 0,2081 |
La transformation logit appliquée aux proportions de survivants figure en colonne 4 du tableau 5. Par exemple, à l’âge de 20 ans, le logit de l20 se calcule comme suit:
La table-type utilisée est une table-type qui tient compte du sida, avec une espérance de vie de e0 = 50 ans. Les logits des survivants de la table-type conditionnelle (qui figurent en colonne 5 du tableau 5) apparaissent en colonne 6 du tableau 5. Comme on peut le voir sur la figure 2, la table-type qui tient compte du sida n’ajuste pas bien les données, mais elle marche mieux que toute autre table-type qui ne tient pas compte de l’impact du sida sur la mortalité.
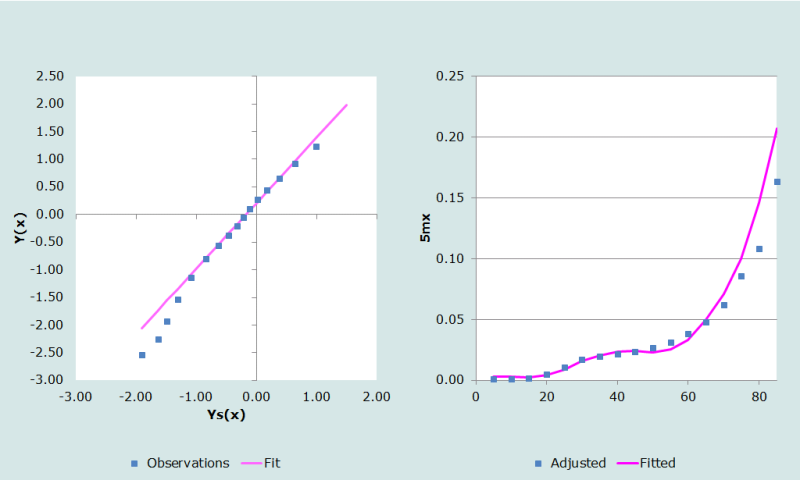
Les coefficients, α et β, sont déterminés comme la pente et l’ordonnée à l’origine de la droite qui ajuste au mieux les transformations logit, qui figurent en colonnes 4 et 6 du tableau 5, dans l’intervalle d’âge choisi par l’utilisateur (entre 45 et 80 ans dans cet exemple), soit ici 0,2119 et 1,1893 respectivement.
On applique ensuite ces coefficients aux logits de la table de mortalité conditionnelle, afin de produire les logits lissés (colonne 7 du tableau 5). Par exemple, pour l’âge de 20 ans, le logit lissé se calcule comme suit :
Ces valeurs sont ensuite prises pour calculer la table de mortalité lissée (colonne 8 du tableau 5). Par exemple, la probabilité de survie à 20 ans se calcule comme suit :
Les personnes-années vécues cumulées au-delà de l’âge x, soit Tx, figurent en colonne 9 du tableau 5, et se calculent à partir de la table de mortalité lissée. Ces valeurs sont alors utilisées pour calculer les taux de mortalité lissés, qui figurent en colonne 10 du tableau 5. Par exemple, à l’âge de 80 ans :
Diagnostics, analyse et interprétation
Contrôles et validation
L’estimation de la complétude est de 91%. La première vérification à faire sur ce résultat est la comparaison avec le résultat correspondant pour l’autre sexe. Ainsi, en appliquant la même méthode décrite pour les hommes aux données concernant les femmes au cours de la même période (voir la feuille de calcul : AM_GGB_South Africa_females) donne une estimation de la complétude de 89%. Des recherches antérieures (Dorrington, Moultrie and Timæus 2004) ont montré que l’on peut s’attendre à des résultats voisins pour les deux sexes, et le fait que ces résultats le sont en effet valide par conséquent ces estimations.
Une seconde vérification des résultats consiste à les comparer avec ceux obtenus par la Méthode de l’extinction des cohortes synthétiques (voir la feuille de calcul : AM_SEG_South Africa_males). Cette méthode donne une estimation de la complétude de 94% sur l’intervalle d’âge de 5 à 84 ans, ce qui est aussi assez proche pour valider les résultats précédents.
Une troisième vérification consiste à comparer diverses estimations de la mortalité avec d’autres sources, telles que des estimations antérieures pour le pays, ou les Perspectives de la population mondiale (UN Population Division 2011). L’estimation du quotient de mortalité de 15 à 60 ans, 45q15, est de 523 pour 1000 après correction pour tenir compte de la sous-déclaration des décès, une valeur très proche des 528 pour 1000 retenue par les Perspectives de la population mondiale pour la période 2000-2005, ce qui une fois encore montre qu’il y a peu de raisons de mettre en question les résultats obtenus par la méthode.
Il est intéressant de remarquer que l’application de la Méthode de Brass de la balance de l’accroissement démographique à ces mêmes données, en prenant pour population moyenne la population au milieu de l’intervalle entre les deux recensements, donne une estimation de 85% lorsqu’on utilise le même intervalle d’âge. Si on augmente l’âge minimal à 35 ans pour ajuster la droite, on augmente l’estimation à 88%, toujours un peu plus faible que l’estimation de 91% produite par la méthode utilisée ci-dessus.
Interprétation
Comme il a déjà été mentionné plus haut, tous les derniers intervalles d’âge entre 75 et plus et 85 ans et plus retenus pour ajuster la droite fournissent des estimations équivalentes de la complétude de l’enregistrement des décès. Par contre, si on s’arrête avant 75 ans et plus, l’estimation augmente, et atteint 100% pour 70 ans et plus, 105% pour 65 ans et plus, et 108% pour 60 ans et plus. Bien qu’il soit probable que le recensement de 2001 et l’enquête de 2007 sous-estiment le nombre d’hommes dans la population, il est vraisemblable que la sous-estimation soit concentrée chez les jeunes adultes, mais improbable qu’elle soit suffisamment forte pour produire une estimation supérieure à 100% pour la complétude de l’enregistrement des décès par rapport au recensement. De plus, toutes choses égales par ailleurs, plus le seuil du groupe d’âge ouvert est bas, moins les estimations de la complétude sont robustes. En conséquence, on préfèrera les estimations plus modestes obtenues avec un groupe d’âge ouvert commençant à un âge plus élevé.
Problèmes d’interprétation spécifiques de la méthode
Source des données sur les décès déclarés
On trouve en général deux types de problèmes avec les données concernant les décès : ceux qui conduisent à un biais de déclaration (sous- ou sur-déclaration) constant par âge, ce qui est précisément ce que la méthode vise à corriger, et ceux qui conduisent à des biais de déclaration qui varient selon l’âge, qui peuvent entraîner une distorsion dans les estimations finales. Bien que l’approche générale reste essentiellement la même quelle que soit la source des données, des sources différentes peuvent être sujettes à des biais spécifiques, qui peuvent avoir un effet sur l’interprétation des résultats. On va illustrer ces cas par des exemples concrets, et d’une manière générale, l’analyse devra prêter attention aux biais suivants dans les données concernant les décès.
(i) Décès déclarés à l’état civil
Si la répartition de la population entre les zones urbaines et rurales (ou une division équivalente) diffère significativement par âge, et que la complétude de la déclaration des décès en milieu urbain est significativement supérieure à celle du milieu rural, alors l’hypothèse que la complétude est indépendante de l’âge sera vraisemblablement violée, et la complétude va tendre à baisser avec l’âge au-delà de 50 ans si la proportion de personnes qui migrent de l’urbain vers le rural au moment de leur retraite. Si on l’ignore, cette violation de l’hypothèse produira probablement une sous-estimation du niveau moyen de la complétude.
(ii) Décès déclarés par les ménages
Ces données sont sujettes à quatre problèmes potentiels :
- Si une proportion significative des ménages sont dissous après le décès d’une personne clé (comme la seule personne à subvenir aux besoins du ménage), alors les décès de ces personnes risquent de ne pas être déclarés, ce qui conduit à violer l’hypothèse que la complétude est constante selon l’âge. Si une proportion significative des décès dans certains groupes d’âge sont relatifs à des individus qui ne vivent pas dans des ménages ordinaires (par exemple, ceux qui vivent dans des maisons pour personnes âgées), la violation de l’hypothèse peut même être encore plus sévère. Mais ce n’est pas encore un problème dans la plupart des pays en développement.
- Dans les situations où les jeunes adultes quittent leur famille lorsqu’ils grandissent, pour aller vivre en ville, il est possible qu’ils soient considérés comme membres de plusieurs ménages (ou d’aucun ménage), et leurs décès peuvent être déclarés plus d’une fois (ou jamais), ce qui conduit encore à une violation de l’hypothèse de déclaration des décès constante selon l’âge. Dans ce cas, on peut en limiter l’impact en ignorant les données concernant les décès d’âge inférieur à un âge donné pour estimer la complétude.
- Erreurs sur la période de référence. Comme il arrive fréquemment qu’il y ait confusion sur la période précise au cours de laquelle on doit déclarer les décès, sans même parler d’erreurs sur la date précise du décès, il est possible que cela se traduise par soit une sous-déclaration, soit une sur-déclaration des décès. En supposant que l’on puisse faire l’hypothèse que ces biais sont indépendants de l’âge des décédés, cette distorsion sera prise en compte dans l’estimation de la complétude, et ne constituera pas un problème pour le calcul des taux de mortalité corrigés.
- La période de référence ne couvre qu’une petite partie de la période intercensitaire. Par exemple, on a fréquemment le cas suivant, où l’on demande aux ménages de déclarer les décès au cours des 12 derniers mois précédant le recensement. Non seulement une période très courte comme celle-ci produit de fortes fluctuations aléatoires, mais de plus le problème qui se pose est d’estimer la population au début de cette période de référence. On illustrera ce point dans les exemples ci-dessous, et on expliquera comment résoudre le problème. Par contre, si en plus on dispose des décès déclarés par les ménages au premier recensement, on peut utiliser les deux ensembles de données sur les décès pour estimer le nombre de décès qui sont produit entre les deux recensements, comme cela a été expliqué ci-dessus. Mais, comme la question sur les décès des 12 derniers mois au sein des ménages n’a été posée que relativement peu fréquemment avant le cycle des recensements des années 2010, il se peut que l’on ait un seul ensemble de données sur les décès. Dans ce cas, en supposant qu’il n’y ait pas de raison de présumer que le schéma par âge de mortalité ait changé rapidement au cours de la période, on recommande de calculer les taux de mortalité par âge pour l’année concernée, et d’appliquer ces taux aux personnes-années vécues au cours de l’intervalle intercensitaire, de manière à obtenir une estimation des décès au cours de la période. Mais si l’on a de bonnes raisons de penser que la mortalité a changé rapidement, par exemple du fait de l’épidémie de VIH/sida, alors cette adaptation va vraisemblablement biaiser les résultats, soit en sous-estimant, soit en surestimant la mortalité, et dans ce cas on ne recommande pas d’utiliser cette méthode de répartition des décès.
(iii) Décès enregistrés dans les centres de santé
On sait peu de choses à propos de cette source de données, ni comment elle fonctionne. On peut cependant supposer que la complétude dépendra de la répartition géographique des centres de santé auprès desquels les données seront collectées. Dans de nombreux pays en développement, ce type de services a tendance à être concentré dans les zones urbaines. Alors, une nouvelle fois, si la proportion de la population vivant en milieu urbain plutôt qu’en milieu rural varie selon l’âge, on ne pourra pas supposer que la complétude est indépendante de l’âge. Il est aussi possible que certaines causes de décès soient plus fréquentes dans les centres de santé, et si ces causes sont importantes en nombre et qu’elles sont liées à l’âge, tout ceci pourrait entrainer une nouvelle violation de l’hypothèse de la complétude constante selon l’âge.
Exemples utilisant les décès déclarés par les ménages dans les recensements et enquêtes
Les exemples présentés ci-dessous utilisent les mêmes données de population que celles qui sont présentées dans les classeurs Excel : AM_GGB_South Africa_males et AM_GGB_South Africa_females, mais on a utilisé les données des décès des 12 derniers mois déclarés par les ménages au recensement de 2001 et à l’enquête de communauté de 2007, au lieu d’utiliser les données de l’état civil pour la période 2001-2007. Ces données figurent dans le tableau 6.
Tableau 6 : Décès déclarés par les ménages au-cours des 12 mois précédant le recensement ou l’enquête, Afrique du sud
Age | Recensement de 2001 |
| Enquête de communauté de 2007 | ||
|---|---|---|---|---|---|
Sexe masculin | Sexe féminin | Sexe masculin | Sexe féminin | ||
0-4 | 35 873 | 32 096 |
| 48 322 | 44 418 |
5-9 | 3 868 | 3 155 |
| 4 505 | 5 216 |
10-14 | 2 590 | 2 284 |
| 3 442 | 3 259 |
15-19 | 5 628 | 5 122 |
| 8 246 | 7 878 |
20-24 | 10 976 | 13 246 |
| 16 360 | 21 702 |
25-29 | 17 787 | 19 727 |
| 27 551 | 35 840 |
30-34 | 20 038 | 18 292 |
| 34 832 | 42 576 |
35-39 | 19 816 | 15 521 |
| 38 061 | 34 809 |
40-44 | 17 417 | 12 124 |
| 33 604 | 28 823 |
45-49 | 15 840 | 10 105 |
| 27 829 | 20 973 |
50-54 | 15 077 | 9 144 |
| 28 223 | 18 891 |
55-59 | 12 781 | 7 755 |
| 22 868 | 13 118 |
60-64 | 13 428 | 10 367 |
| 18 775 | 14 912 |
65-69 | 11 820 | 10 195 |
| 17 532 | 14 298 |
70-74 | 11 885 | 10 809 |
| 14 879 | 14 645 |
75-79 | 8 794 | 8 393 |
| 12 966 | 14 151 |
80-84 | 7 484 | 9 371 |
| 9 204 | 12 063 |
85+ | 7 115 | 12 389 |
| 11 735 | 18 178 |
Les effectifs de décès qui se sont produits entre la date du recensement (nuit du 9 au 10 octobre 2001) et la date de l’enquête de communauté (supposée être la nuit du 14 au 15 février 2007) sont estimés dans les feuilles de calcul suivantes : AM_Estimating deaths_South Africa_males_hhd et AM_Estimating deaths_South Africa_females_hhd.
L’application de la méthode généralisée de la balance de l’accroissement démographique à ces données pour les hommes est fournie dans la feuille de calcul : AM_GGB_South Africa_males_hhd. Les résultats suggèrent que les décès sont approximativement aussi bien déclarés que ceux de l’état civil. Cependant, l’estimation du quotient de mortalité de 15 à 60 ans, 45q15, est de 548 pour 1000, ce qui est un peu plus élevé que l’estimation produite par les données de l’état civil (523 pour 1000). Mais lorsqu’on applique la méthode généralisée de la balance de l’accroissement démographique aux données du sexe féminin, (voir le classeur Excel AM_GGB_South Africa_females_hhd), on trouve une complétude des décès de femmes déclarés par les ménages inférieure à celle obtenue par les décès de l’état civil. On trouve donc une estimation du quotient de mortalité de 15 à 60 ans, 45q15, de 509 pour 1000, bien supérieure aux 420 pour 1000 obtenus par les décès de l’état civil, et bien moins plausible si on la compare au quotient obtenu pour les hommes.
On peut rechercher les raisons pour lesquelles la méthode semble moins bien marcher lorsqu’elle est appliquée aux décès de sexe féminin déclarés par les ménages en comparant les effectifs de décès calculés d’après les décès déclarés par les ménages aux effectifs de décès attendus par ceux de l’état civil après correction du sous-enregistrement, comme cela apparaît dans le tableau 7. Cette comparaison montre que le nombre de décès de femmes de 55 ans et plus est nettement plus faible. Ceci pourrait être dû au fait que les ménages sont dissous après le décès de ces femmes, car il est fréquent que les femmes qui décèdent à cet âge aient été le chef du ménage.
La comparaison suggère aussi un sur-enregistrement des décès d’hommes de moins de 30 ans et de femmes de moins de 25 ans. Ceci pourrait être dû au fait que leurs décès sont déclarés dans plusieurs ménages, ou au fait que l’état civil est moins complet chez les moins de 25 ans.
Tableau 7 : Rapport des estimations des décès déclarés par les ménages aux décès attendus, déclarés à l’état civil après correction du sous-enregistrement, Afrique du sud
Age | Sexe masculin |
| Sexe féminin | ||||
|---|---|---|---|---|---|---|---|
Déclarés | Attendus | Rapport | Déclarés | Attendus | Rapport | ||
0-4 |
| ||||||
5-9 | 22 683 | 17 193 | 132% |
| 22 995 | 14 670 | 157% |
10-14 | 16 462 | 12 378 | 133% |
| 15 173 | 10 417 | 146% |
15-19 | 38 013 | 28 134 | 135% |
| 35 666 | 27 050 | 132% |
20-24 | 74 934 | 60 701 | 123% |
| 95 993 | 85 167 | 113% |
25-29 | 124 403 | 113 541 | 110% |
| 152 718 | 155 452 | 98% |
30-34 | 150 792 | 160 796 | 94% |
| 166 488 | 171 801 | 97% |
35-39 | 159 016 | 161 141 | 99% |
| 137 837 | 142 328 | 97% |
40-44 | 140 172 | 150 136 | 93% |
| 111 910 | 116 506 | 96% |
45-49 | 120 016 | 133 651 | 90% |
| 85 284 | 94 022 | 91% |
50-54 | 118 989 | 122 768 | 97% |
| 76 941 | 82 330 | 93% |
55-59 | 97 977 | 106 972 | 92% |
| 57 353 | 72 605 | 79% |
60-64 | 88 088 | 99 325 | 89% |
| 69 220 | 79 395 | 87% |
65-69 | 80 451 | 91 497 | 88% |
| 67 007 | 86 665 | 77% |
70-74 | 72 827 | 80 666 | 90% |
| 69 536 | 94 017 | 74% |
75-79 | 59 632 | 70 543 | 85% |
| 61 942 | 88 894 | 70% |
80-84 | 45 365 | 53 194 | 85% |
| 58 410 | 77 590 | 75% |
85+ | 51 779 | 51 021 | 101% |
| 83 753 | 108 712 | 77% |
Pour simuler une situation dans laquelle seul le dernier recensement possède la question sur les décès des 12 derniers mois, on calcule ici une estimation du nombre de décès dans chaque groupe d’âge entre l’instant du recensement de 2001 et l’enquête de communauté de 2007 en utilisant seulement les décès déclarés à l’enquête de communauté de 2007 selon la formule suivante :
En appliquant la méthode à ces nouveaux effectifs de décès, on trouve des estimations des quotients de mortalité à 15-59 ans, 45q15 , de 586 pour 1000 chez les hommes et de 578 pour 1000 chez les femmes. Mais, à la différence des estimations précédentes, ce sont des estimations de mortalité qui se rapportent essentiellement à l’année qui précède l’enquête de 2007. On pouvait donc s’attendre à une mortalité plus forte que la moyenne de la période 2001-2007 car la mortalité était en augmentation au cours de la période du fait de l’épidémie de VIH/sida. Il est bien évident que lorsqu’on fait une estimation à partir des décès d’une seule année (qui plus est provenant d’une enquête par sondage, sur un échantillon relativement faible) on peut s’attendre à des résultats moins fiables, ce qui semble être le cas ici, surtout pour les femmes. D’autres estimations faites pour l’année 2006 (Bradshaw, Dorrington and Laubscher 2012) donnent des valeurs proches de 550 pour 1000 chez les hommes et de 450 pour 1000 chez les femmes.
Description détaillée de la méthode
Exposé mathématique
La méthode généralisée de la balance de l’accroissement démographique suit la même logique que la méthode de Brass de la balance de l’accroissement démographique (Brass 1975). Cette dernière a pour origine les travaux de Carrier (1958), qui le premier a proposé une méthode d’estimation de la mortalité à partir de la distribution par âge de décès. La méthode est fondée sur une relation simple, l’équation de l’équilibre des populations, que l’on suppose par convention être fermée aux migrations. Dans une telle population fermée, le nombre de personnes vivantes au temps t2 est égal au nombre de personnes vivantes au temps t1 plus les naissances qui se produisent entre les instants t1 et t2, moins les décès qui se produisent entre les instants t1 et t2, qui peut s’écrire : où B sont les naissances et D sont les décès qui se produisent entre les instants t1 et t2. On peut généraliser cette équation à la population d’âge x et plus. Dans ce cas, les naissances correspondent aux personnes qui atteignent leur x-ème anniversaire au cours de la période entre les instants t1 et t2, noté , et les décès sont les décès d’âge x et plus qui se produisent entre les instants t1 et t, noté . L’équation s’écrit alors :
(1)
L’équation (1) peut se réécrire comme suit :
.
On peut diviser les deux termes par les personnes-années vécues au cours de la période entre les instants t1 et t2, soit :
et l’équation de la balance de l’accroissement démographique s’écrit :
(2)
où
et
On appelle souvent les taux b(x+) et d(x+) respectivement les ‘taux partiels’ de natalité et de mortalité, ou parfois les ‘taux segmentiels’ (segmental birth and death rates).
Ces relations ne sont vérifiées que dans le cas où l’enregistrement des décès est complet pour tous les âges entre les instants t1 et t2, que les âges sont exacts, et qu’il en va de même pour le décompte de la population aux instants t1 et t2.
Supposons maintenant qu’au lieu d’un enregistrement complet, seule une certaine proportion de décès sont déclarés, la même à tous les âges, et qu’il en va de même pour les recensements de population, c'est-à-dire qu’une certaine proportion est recensée, qui peut être différente d’un recensement à l’autre, et différente de celle des décès. On a alors, au lieu des vraies valeurs : , et des valeurs déclarées, notées : , et telles que : , et
Alors, si on utilise les approximations suivantes :
et
alors on a :
où
et
et où
L’équation 2 devient alors :
c’est-à-dire :
avec :
et
On peut donc résoudre cette équation pour k1, k2 et c, en faisant l’hypothèse que la complétude du meilleur des recensements est de 100%, c'est-à-dire en prenant la valeur du maximum de k1 et k2 = 1.
Ajustement de la droite de régression
Deux aspects doivent être considérés pour ajuster au mieux la droite qui décrit la relation entre le taux partiel de natalité et le taux partiel de mortalité : le choix de la méthode de régression, et le choix des points qui sont retenus pour calculer la pente et l’ordonnée à l’origine.
L’ajustement d’une droite en utilisant une régression non-pondérée et la méthode des moindres carrés n’est pas recommandé ici, car il donne trop de poids aux points aberrants qui ne sont pas fiables, surtout ceux qui représentent les âges élevés. On recommande plutôt une méthode plus robuste, telle que la ligne des moyennes (mean line), c’est-à-dire la droite qui joint deux points fixes, qui eux-mêmes sont les moyennes en abscisse et en ordonnée de la première moitié et de la seconde moitié des points correspondant à l’intervalle d’âge retenu. On peut aussi utiliser la ligne des moyennes tronquées (trimmed mean line) : c’est une ligne analogue, qui joint deux points fixes qui eux-mêmes sont les moyennes pondérées des points, les pondérations étant choisies pour donner moins de poids aux points qui sont moins fiables, en général les points situés aux extrémités. Ces méthodes sont expliquées en détail dans le Manuel X (UN Population Division 1984: 147–148). Une autre alternative est décrite dans le Manuel des Nations Unies sur la Mortalité Adulte (UN Population Division 2002: 105–110). Cette méthode est là encore analogue à la méthode de la ligne des moyennes, mais dans ce cas on divise les points en trois groupes de même taille, et on choisit la droite qui joint les médianes des points en abscisse et en ordonnée correspondant au premier tiers et au dernier tiers des points classés par âge.
Mari Bhat signale que chaque méthode a ses points faibles (Bhat 2002). Puisque les taux partiels de natalité et de mortalité sont traités tous deux comme des variables dépendantes, il propose d’utiliser la régression orthogonale comme la meilleure méthode pour tenir compte d’éventuelles erreurs sur les âges. Cette stratégie permet de tenir compte à la fois des distances horizontales et verticales à la ligne de régression, puisqu’elle minimise la somme des carrés des résidus orthogonaux (ORSS), définis comme suit :
L’utilisation de cette méthode conduit à calculer la complétude de la déclaration des décès, c, comme le rapport des écarts-types des taux partiels de mortalité et de natalité. La valeur de l’ordonnée à l’origine est la différence entre la moyenne des taux partiels de natalité et la moyenne des taux partiels mortalité divisés par c. C’est cette approche qui est utilisée dans l’application de la méthode de Brass de la balance généralisée de l’accroissement démographique présentée dans le classeur Excel joint à ce manuel.
Limites de la méthode
Cette méthode est moins vulnérable aux erreurs sur l’âge que la Méthode de l’extinction des cohortes synthétiques. Cependant, la tendance fréquente à exagérer l’âge au décès tel qu’il est déclaré (par rapport à l’âge déclaré au recensement) se manifestera dans le graphique : les points correspondants à l’intervalle d’âge où l’âge est exagéré auront tendance à se placer en-dessous de la droite de régression. On peut alors traiter ce problème en diminuant l’âge de début du dernier intervalle, en le choisissant en-dessous de l’âge qui correspond aux points qui font problème.
Les migrations ne sont pas prises en compte par ce modèle, mais elles peuvent affecter la population des jeunes adultes (surtout entre 20 et 35 ans). Elles ont en général beaucoup moins d’effet sur les décès, car ceux-ci sont concentrés aux âges élevés. Ignorer les immigrations va tendre à diminuer la pente de la droite, et donc à surestimer le sous-enregistrement des décès, et par conséquent à sous-estimer les taux de mortalité corrigés. Ignorer les émigrations aura l’effet contraire.
Les estimations du nombre de migrations nettes par âge au cours de la période intercensitaire font souvent défaut. Dans une telle situation, on peut procéder en suivant les recommandations suivantes. Si les migrations sont importantes mais restent inconnues, et que les points situés au-delà de l’âge de 30 ans sont bien alignés, on peut estimer la complétude en ajustant une droite restreinte aux points correspondants aux âge de 35 ans et plus. Si les migrations sont peu importantes, certains démographes préconisent d’ajuster une droite en partant de l’âge de 5 ans, pour réduire cette distorsion, en faisant l’hypothèse que toute différence entre le sous-enregistrement des décès à ces âges jeunes et celui aux âges élevés n’entrainera pas de distorsion sensible, puisque la mortalité reste très faible entre 5 et 14 ans. Dans le cas où les migrations sont peu importantes, d’autres auteurs (Hill, You and Choi 2009) proposent une autre stratégie : on pourrait obtenir une meilleure estimation en prenant la moyenne entre l’estimation de la complétude obtenue avec cette méthode et celle obtenue en appliquant la méthode de l’extinction des cohortes synthétiques aux mêmes données. Il reste possible que ces adaptations produisent de meilleurs estimations que celles obtenues en ignorant les migrations, mais on ne dispose que de peu de recherches sur ce point, ainsi que sur la précision des estimations de la complétude obtenues en procédant à de telles adaptations.
Les variations de la complétude de la déclaration des décès en fonction de l’âge peuvent introduire une courbure dans l’alignement des points du graphique. En conséquence, une des forces de cette méthode est que si les points qui représentent les groupes d’âge successifs sont approximativement situés sur une ligne droite, on peut alors raisonnablement supposer que la complétude est approximativement constante selon l’âge. Mais si certains points sont sur la ligne, et que d’autres en sont éloignés, une méthode pour décider quels points rejeter consiste à calculer le taux partiel de croissance pour chacun des intervalles ouverts successifs, et de garder seulement les points pour lesquels les valeurs de sont assez cohérentes.
Une des principales limites de cette méthode est peut-être que la valeur du diagnostic fait à partir de la représentation graphique des taux partiels de natalité et de mortalité reste faible, hormis les exceptions mentionnées ci-dessus.
Extensions de la méthode
Si les âges sont précis, et si l’hypothèse de la couverture constante par âge des recensements est vérifiée, alors la méthode peut être adaptée aux cas où la complétude de la déclaration des décès n’est constante que sur un intervalle d’âges limité, (x to x + n). Dans ce cas on restreint le groupe d’âge choisi pour l’équation de la balance de la croissance démographique. L’équation 2 devient alors :
,
où
et
La partie gauche de l’équation de régression qui correspond aux observations sélectionnées devient alors : . Mais on a très peu d’expérience sur la manière dont cette approche alternative fonctionne en pratique, probablement parce que les données des pays en développement sont rarement assez précises.
Autres lectures et références
L’analyse de la sensibilité de cette méthode aux erreurs de données les plus fréquentes et aux violations des hypothèses reste assez limitée. Toutefois, on renvoie le lecteur à Hill, You et Choi (2009) pour ce qui concerne les hypothèses de la méthode de la répartition des décès dans les populations sans sida, et à Dorrington et Timæus (2008) pour le cas des populations souffrant d’une forte épidémie de VIH/sida. Murray, Rajaratnam, Marcus et al. (2010) ont utilisé des simulations stochastiques et conclu que ces méthodes ne sont pas vraiment fiables. Mais leur travail n’a eu jusqu’ici qu’un impact très limité sur l’utilisation de ces méthodes, peut-être parce que ces auteurs ne fournissent que peu de détails sur la description de leurs simulations, ou peut-être que leur étude est basée sur des hypothèses irréalistes concernant une fréquence élevée des migrations.
Bhat M. 2002. "General Growth Balance method: A reformulation for populations open to migration", Population Studies 56(1):23-34. doi: https://dx.doi.org/10.1080/00324720213798
Blacker J. 1988. An Evaluation of the Pakistan Demographic Survey. Karachi: Pakistan Federal Bureau of Statistics.
Bradshaw D, RE Dorrington and R Laubscher. 2012. Rapid Mortality Surveillance Report 2012. Cape Town: South African Medical Research Council. https://www.mrc.ac.za/bod/RapidMortality2011.pdf
Brass W. 1975. Methods for Estimating Fertility and Mortality from Limited and Defective Data. Chapel Hill NC: Carolina Population Centre.
Carrier NH. 1958. "A note on the estimation of mortality and other population characteristics, given death by age", Population Studies 12(2):149-163. doi: https://dx.doi.org/10.2307/2172187
Division de la Population des Nations Unies. 1984. Manuel X. Techniques indirectes d’estimation démographique. New York : Nations Unies, Département des affaires économiques et sociales internationales, ST/ESA/SER.A/81. https://unstats.un.org/unsd/demographic/standmeth/handbooks/Manuel_X-fr.pdf
Dorrington RE, TA Moultrie and IM Timæus. 2004. Estimation of mortality using the South African 2001 census data. Monograph 11. Centre for Actuarial Research, University of Cape Town. https://blogs.lshtm.ac.uk/iantimaeus/files/2024/03/Dorrington-Moultrie-Timaeus-Mono11.pdf
Dorrington RE and IM Timæus. 2008. "Death Distribution Methods for Estimating Adult Mortality: Sensitivity Analysis with Simulated Data Errors, Revisited," Paper presented at Population Association of America 2008 Annual Meeting. New Orleans, Louisiana, 17-19 April.
Hill K. 1987. "Estimating census and death registration completeness", Asian and Pacific Census Forum 1(3):8-13, 23-24. https://hdl.handle.net/10125/3602.
Hill K, D You and Y Choi. 2009. "Death distribution methods for estimating adult mortality: Sensitivity analysis with simulated data error", Demographic Research 21(Article 9):235-254. doi: https://dx.doi.org/10.4054/DemRes.2009.21.9
Murray CJL, JK Rajaratnam, J Marcus, T Laakso and AD Lopez. 2010. "What can we conclude from death registration? Improved methods for evaluating completeness", PLoS Med 7(4):e1000262. doi: https://dx.doi.org/10.1371/journal.pmed.1000262
Timæus IM. 2007. "Impact of HIV on mortality in Southern Africa: Evidence from demographic surveillance", in Caraël M and JR Glynn (eds). HIV, Resurgent Infections and Population Change in Africa, Springer, pp 229–243. doi: https://dx.doi.org/10.1007/978-1-4020-6174-5_12
UN Population Division. 2002. Methods for Estimating Adult Mortality. New York: United Nations, Department of Economic and Social Affairs, ESA/P/WP.175. https://www.un.org/esa/population/techcoop/DemEst/methods_adultmort/methods_adultmort.html
UN Population Division. 2011. World Population Prospects: The 2010 Revision, Volume I: Comprehensive Tables. New York: United Nations, Department of Economic and Social Affairs, ST/ESA/SER.A/313. https://www.un.org/development/desa/pd/sites/www.un.org.development.desa.pd/files/files/documents/2020/Jan/un_2010_world_population_prospects-2010_revision_volume-i_comprehensive-tables.pdf
- Printer-friendly version
- Log in to post comments